
Présentation de Trio — Un modèle mondial pour les opérations physiques
Une mise à jour de statut d'IoTeX sur Trio, l'IA dans le monde réel, et notre réponse au premier défi de l'Anti-Roadmap.
En mars, IoTeX a publié son Anti-Roadmap pour 2026 — trois défis au lieu d'un calendrier. Le défi 1 était celui de l'existence : devenir l'interface de l'IA avec le monde physique. Notre réponse était concrète — vision d'abord, transformer tout flux en direct en une intelligence que vos opérations physiques peuvent exploiter en temps réel. Cette réponse est Trio, un modèle mondial pour les opérations physiques, construit au MachineFi Lab par l'équipe centrale derrière IoTeX. Nous avons relevé le défi, et maintenant nous livrons.
Tout au long de l'histoire, le monde physique a été dirigé par des personnes. Une personne observe ce qui se passe, juge ce que cela signifie, et agit en conséquence — conduit le camion, travaille à la chaîne, marche dans l'entrepôt. Percevoir, prédire, agir : cette boucle a toujours eu besoin d'un humain.
L'IA a d'abord changé le monde numérique — langage, code, images. Maintenant, elle commence à s'attaquer au monde physique. Une IA qui conduit une voiture à travers le trafic en direct. Une IA qui apprend un jeu vidéo en imaginant comment il se joue. Un robot qui plie une pile de linge. La partie sous-jacente à toutes celles-ci — ce qui permet à une machine d'observer une situation, d'imaginer ce qui se passe ensuite, et d'agir — est un modèle mondial. Trio est un nouveau type de modèle mondial : celui qui donne à l'IA une vision d'une opération entière, en direct.

Ces autres sont étroits par choix : une voiture, un jeu, un robot, une tâche. Mais la plus grande surface physique de toutes est déjà câblée et observe — les caméras sur chaque entrepôt, magasin, usine, et ligne de soins… Un modèle mondial qui fonctionne sur celles-ci — sur des opérations entières, en direct — est exactement l'interface que le défi 1 a demandée. C'est pour cela que Trio a été conçu.
Ce qu'est Trio
Remarquez ce que ces quatre ont en commun : chacun gère une seule chose — une voiture, un jeu, un robot, un monde virtuel. Aucun d'eux ne gère une opération. Et c'est là que réside la majeure partie de l'économie physique — un restaurant lors du coup de feu déjeuner, une station de lavage de voitures traitant des voitures dans ses baies, un entrepôt chargeant des camions, un magasin gérant son espace, une chaîne d'usine — des endroits avec des dizaines de personnes, de véhicules et de machines se déplaçant en même temps, 24 heures sur 24, tous surveillés par des caméras que personne n'a le temps de regarder.

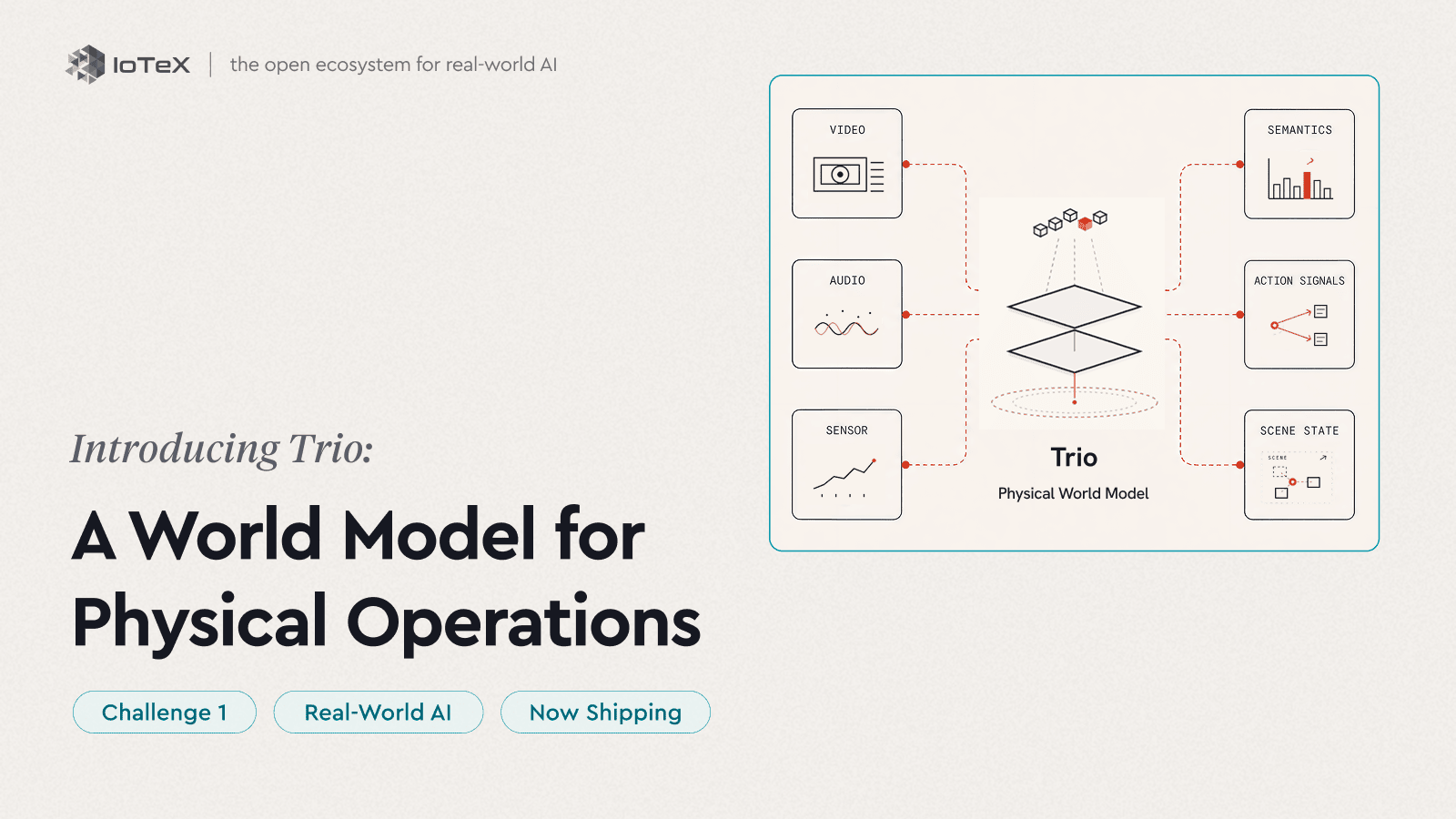
C'est pour cela que Trio est conçu. Trio est notre modèle mondial pour les opérations physiques — non pas un modèle monolithique unique, mais un ensemble de trois produits qui, ensemble, perçoivent, prédisent et agissent sur une opération en direct. Là où un modèle linguistique apprend comment fonctionne le texte, Trio apprend comment fonctionne un lieu — ce qu'il contient, comment il se déplace, ce qui se passe ensuite — pour votre opération, à partir des caméras et des capteurs que vous avez déjà. Nous ne remplaçons pas les modèles linguistiques ; nous leur donnons le monde physique.
Trio exécute cette boucle en trois étapes — et il est livré dans cet ordre. La perception est en direct aujourd'hui ; la prévoyance et l'action sont ce qui vient ensuite.
PERCEPTION → PRÉDICTION → ACTION
- Perception — Voir · Comprendre — Trio-Rétine · Trio-Lumen — Live maintenant
- Prédiction — Prévoir · raisonner à l'avance — Suivant
- Action — Clore la boucle — Plus tard
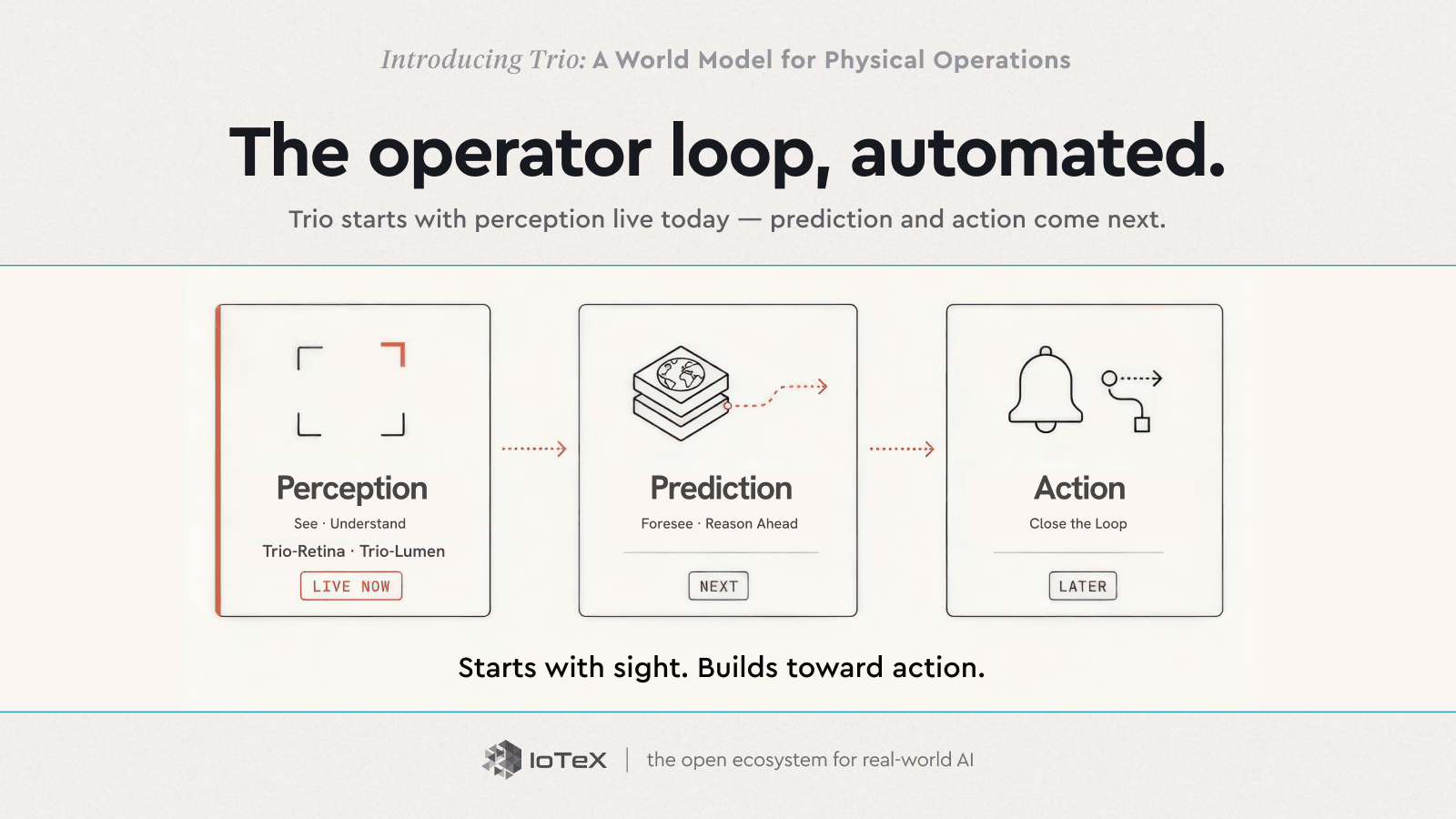
Aujourd'hui, deux de ces éléments sont réels et entre vos mains. Trio-Rétine (Voir) transforme tout flux de caméra en une seule lecture standard, en direct, de ce qui se passe — qui est où, ce qu'ils font, où ils vont. Trio-Lumen (Comprendre) rend cela programmable en anglais simple — "alerter quiconque dans le quai de chargement après les heures" — surveillant chaque image 24 heures sur 24 et transformant cela en événements et alertes. Perception et compréhension, livraison aujourd'hui.
pip install trio-retinaTrio-Retina est open source — fonctionne sur votre propre machine, ou essayez-le en direct dans le Playground.Ces deux-là sont les fondations sur lesquelles le reste est construit. La prévoyance et l'action — anticiper les problèmes avant qu'ils ne se produisent, puis agir sur le terrain — sont les prochaines étapes de la boucle. L'ordre est délibéré : vous ne pouvez pas prévoir ce que vous ne pouvez pas encore voir, donc nous avons d'abord construit la vue.
Un modèle formé sur l'internet ouvert apprend à quoi ressemble le monde. Trio apprend comment votre opération fonctionne.
À Quoi Cela Ressemble Dans Un Entrepôt
Ressortez l'abstraction. Un quai de chargement, en milieu de service. Un chariot élévateur recule d'un berceau ; un employé sort entre deux étagères sur un chemin qui le croise. Aucun ne peut encore voir l'autre.
Voir — Trio-Retina, fonctionnant sur une petite boîte à côté de la caméra, a déjà les deux comme objets suivis : le chariot élévateur et la personne, leurs positions, et où chacun se dirige.
Prévoir — Le modèle du monde de Trio fait avancer les deux prochaines secondes. Les deux chemins se croisent. Il a déjà vu cette géométrie exacte mal se terminer auparavant.
Agir — une porte de sécurité à bord déterministe déclenche l'alarme d'intersection en environ 50 millisecondes — plus vite que l'un ou l'autre pourrait réagir — et le chariot élévateur est signalé pour s'arrêter. Un quasi-accident au lieu d'un rapport d'incident.
C'est toute la thèse dans un seul cadre : pas des images que vous faites apparaître après qu'il se soit passé quelque chose, mais une décision prise à l'instant avant que cela ne se produise.

Un Modèle Du Monde Réel — et Comment Le Notre Est Différent
Trio est situé dans un domaine en rapide mouvement. Les modèles du monde sont là où pointent maintenant beaucoup des meilleures têtes de l'IA. L'idée remonte à World Models de Ha & Schmidhuber (2018) — un agent apprenant un modèle compact de son environnement et "rêvant" des rollouts à l'intérieur. Yann LeCun soutient qu'un modèle mondial prédictif dans l'espace latent (son JEPA) est le maillon manquant sur le chemin vers une intelligence machine autonome ; Fei-Fei Li appelle la frontière intelligence spatiale, et ses World Labs construisent des modèles qui génèrent des mondes 3D explorables. Le domaine se divise à peu près en camps :
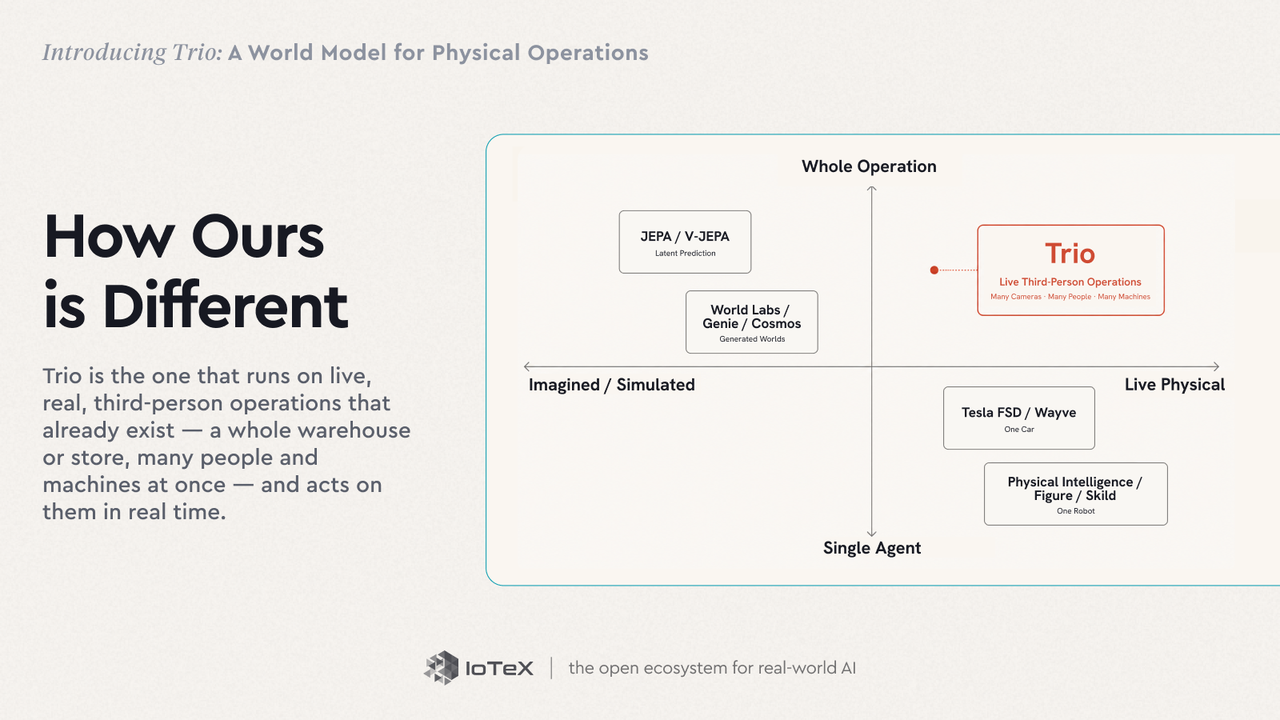
- Prédiction latente — V-JEPA 2 (Meta) et la ligne Dreamer apprennent les dynamiques dans l'espace latent et planifient à l'intérieur.
- Mondes génératifs et interactifs — Genie 3 (DeepMind), NVIDIA Cosmos, et le Marble de World Labs imaginent et génèrent des environnements.
- Conduite — Tesla FSD et GAIA-2 de Wayve mettent en œuvre les modèles du monde les plus déployés sur Terre — pour une voiture.
- Robotique — Physical Intelligence, Skild AI, et Figure construisent des modèles de base pour un seul robot.
Presque tous d'entre eux imaginent ou simulent un monde, ou modélisent le domaine égo-centré d'un agent unique — une voiture, un robot. Trio est celui qui fonctionne sur des opérations en direct, réelles, de tierces personnes qui existent déjà — un entrepôt ou un magasin entier, de nombreuses personnes et machines à la fois — et agit sur eux en temps réel.

Deux axes distinguent Trio. Techniquement — c'est petit, rapide et spécialisé : temps réel à la périphérie, un coût près de 0,004 $ par requête, facturé par décision, une fondation gelée plus de petits adaptateurs par site (LoRA, formés en heures GPU) plutôt qu'un modèle général géant relancé sur chaque cadre. Sur l'évaluation OVBench, envelopper un modèle à poids ouverts dans la pile de Trio augmente l'exactitude de +2,3 points uniquement grâce à l'architecture, et ses flux de perception fonctionnent sans les limites minutées fixes que les modèles de pointe atteignent. Par scénario — il fonctionne sur les opérations qui existent déjà et agit sur elles maintenant, au lieu d'imaginer un monde, de conduire une voiture ou de déplacer un robot.
Comment Trio est construit
Pour les équipes techniques : voici comment Trio reste suffisamment rapide et bon marché pour fonctionner sur chaque caméra, toute la journée. Si vous êtes ici pour l'histoire des opérations, parcourez — le bénéfice est dans la dernière ligne.
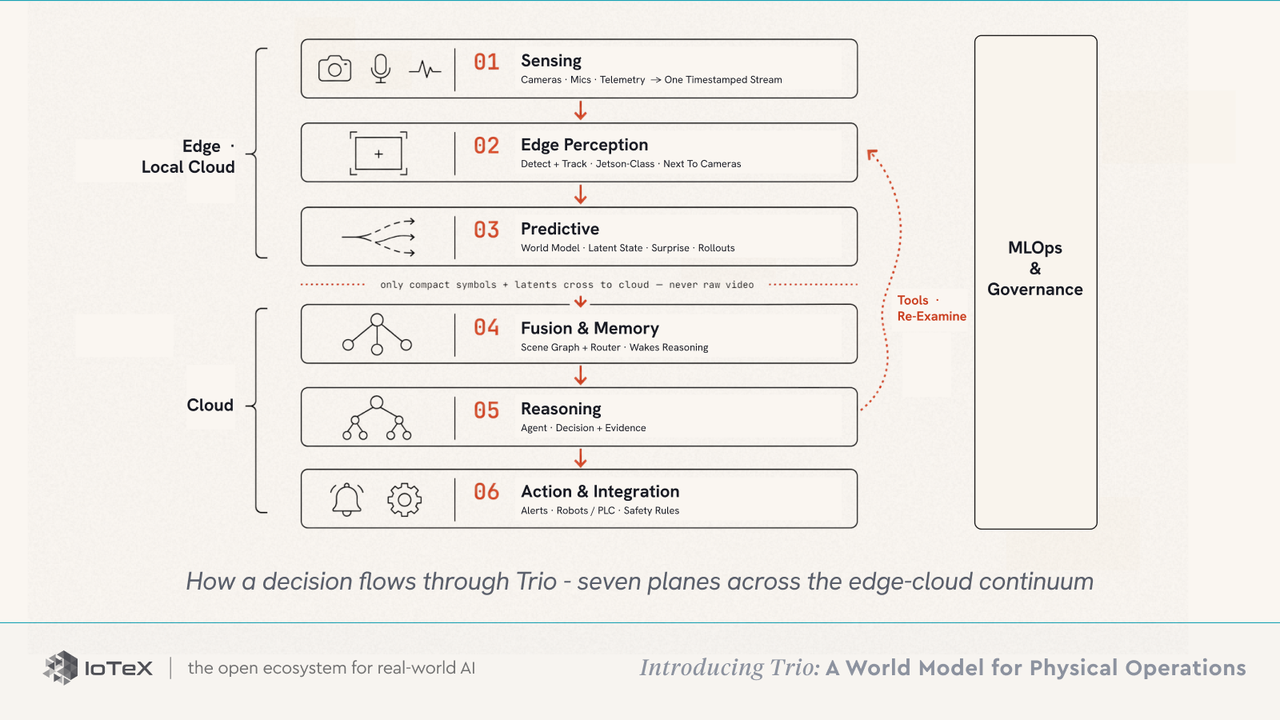
Cinq principes maintiennent le système ensemble : chaque interface entre les couches est un graphique de scène fortement typé et inspectable (jamais un vecteur opaque) ; un routeur détient le coût, exécutant les couches bon marché en continu et réveillant le raisonnement coûteux uniquement lorsque nécessaire ; les outils sont bidirectionnels, de sorte que la couche de raisonnement peut ordonner aux couches inférieures de réexaminer ou de re-simuler ; chaque décision est accompagnée de ses preuves, de sorte qu'un opérateur peut inspecter, contester et remplacer ; et les modèles de base restent figés tandis que de petits adaptateurs par déploiement — modules LoRA et un adaptateur de fusion inter-niveaux, formés en heures GPU plutôt qu'un réentraînement complet — spécialisent chaque site.
Ces principes se réalisent sous la forme de sept plans — six sur le chemin d'une seule décision, plus la gouvernance à travers tous : Perception (caméras · micros · télémétrie → un flux horodaté) → Perception à la périphérie (détecter + suivre, classe Jetson, à côté des caméras) → Prédictif (modèle mondial : état latent · surprise · réalisations) → Fusion et Mémoire (graphique de scène + routeur qui réveille le raisonnement) → Raisonnement (agent → décision associée à ses preuves) → Action et Intégration (alertes · robots / PLC · règles de sécurité indépendantes), avec MLOps et Gouvernance à travers tout cela.
Parce que la perception et la prédiction fonctionnent localement et que seuls des symboles compacts et des latents voyagent vers le cloud — jamais de la vidéo brute — Trio est facturé par décision, pas par jeton par cadre.
Où Trio fonctionne
Le dépôt était un cadre. Le restaurant, le lavage de voitures, le magasin, l'usine avec laquelle nous avons commencé — le même modèle pointe vers toute opération qui fonctionne sur des caméras, aujourd'hui aux côtés des opérateurs humains, mettant en lumière ce que leurs systèmes existants manquent :
- Opérations de franchise — Gestion des files d'attente, réduction des pertes, conformité des employés, analyses des flux de clients.
- Sécurité et Accès — Détection d'intrusion, analyse de flânerie, prévention de queues, application en dehors des heures.
- Logistique et Entrepôt — État des quais, temps de présence des véhicules, conformité aux EPI, application des SOP de sécurité à travers les cours et les étages.
- Fabrication et Industrial — Surveillance de la ligne, détection de défauts, alertes de danger à travers chaque ligne et zone de machine.
- Villes intelligentes — Stationnement, flux de circulation, sécurité publique, surveillance des infrastructures à travers les rues et le transport.
- Santé et Sciences de la Vie — Détection de chutes, modèles d'occupation, surveillance comportementale à travers des chambres et des campus de résidents.
- Hôtellerie et Lieux — Gestion de la foule, contrôle d'accès aux zones VIP, réponse en temps réel aux incidents à grande échelle.
- Infrastructure Critique — Renseignement périphérique 24/7, détection d'intrusion, réponse autonome pour les sites qui ne peuvent pas manquer une alerte.
Ce que nous avons construit — et ce qui est à venir
Trio n'est plus une thèse sur un tableau blanc. Le rapport technique v1.0 formalise le système complet — la pile perception-prédiction-action, cinq principes, sept plans — avec deux domaines de référence entièrement travaillés (un lavage de voiture et un dépôt), jusqu'à la quasi-collision entre chariot élévateur et piéton ci-dessus, capturée par une porte de sécurité déterministe à la périphérie qui s'active en environ 50 millisecondes, bien en dessous du plafond de 100 ms. Trio-Retina est open source (pip install trio-retina), et le Playground est en direct — ouvrez-le et regardez Trio lire des séquences réelles dans votre navigateur.
Trois forces font maintenant le moment : le silicium de pointe peut enfin exécuter un raisonnement opérationnel en temps réel sans un retour dans le cloud ; la compréhension de scènes multi-entités a franchi un seuil de recherche que la détection d'objets uniques n'a jamais approché ; et les opérateurs des environnements physiques sont prêts pour ce qui pourrait être la capacité la plus sous-évaluée de l'IA aujourd'hui — un modèle mondial basé sur les caméras qu'ils possèdent déjà, sans nouveau matériel. De là, Trio grandit dans la boucle — de voir et comprendre aujourd'hui vers prévoir et, avec le temps, agir sur le terrain.
Commencez avec Trio aujourd'hui
Deux voies d'entrée — les deux sont actives en ce moment :
CONSTRUISEZ-LE · DÉVELOPPEURS — Trio-Retina sur GitHub. Le niveau de perception open-source — le niveau d'état agnostique au modèle qui transforme n'importe quel détecteur en un flux standard d'événements plus un état latent. pip install trio-retina et exécutez-le sur votre propre machine.
EXPÉRIMENTEZ-LE · OPÉRATEURS — Trio-Lumen sur la plateforme. Voyez votre opération prendre vie dans le navigateur — Trio lisant des séquences réelles comme des objets avec état et des foules comme un flux, puis pointez-le vers vos propres caméras et demandez en anglais simple.
Trio, IoTeX, et l'Économie Machine
Trio ne vient pas de nulle part. Il est construit sur une décennie d'IoTeX — l'infrastructure et le réseau d'appareils connectés, les identités de dispositifs (ioID), les données machine vérifiables (Quicksilver), et les paiements machine à machine (x402) dont l'IA du monde réel a besoin pour se poser dans le monde avec des données, une identité, et la confiance derrière elle. Et Trio est le produit qui rend la vision d'IoTeX concrète : le Challenge 1 avait pour objectif de faire d'IoTeX l'interface à travers laquelle l'IA voit, vérifie et agit sur le monde physique, et Trio est le voyant.
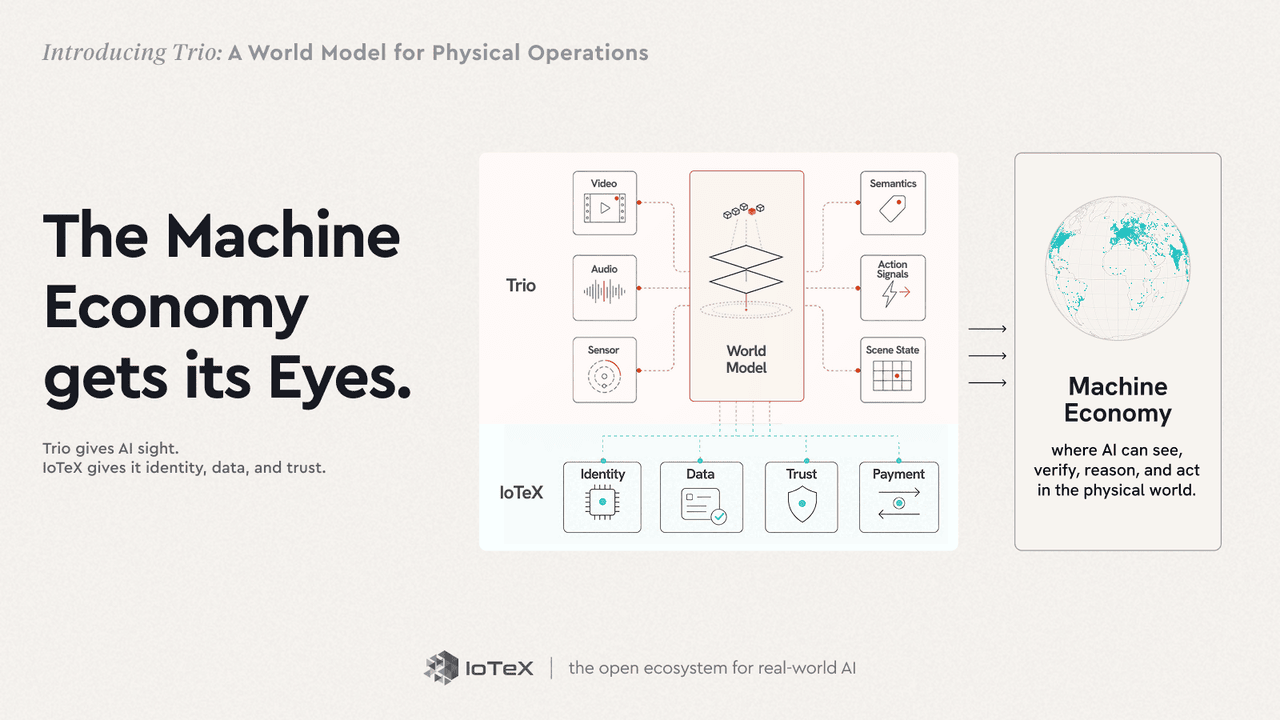
Mettre tout cela ensemble et vous avez l'économie machine décrite dans l'Anti-Roadmap. Les machines ont besoin de trois choses : voir le monde, faire confiance à ce qu'elles voient, et agir dessus. IoTeX fournit la confiance décentralisée, tandis que Trio fournit les yeux et les oreilles pour percevoir la réalité physique — et le cerveau pour raisonner et agir dessus.
Continuez à livrer...
Le Challenge 1 a maintenant une réponse. Donnez à l'IA des yeux sur le monde physique et rendez-le réel — c'était le premier et le plus existentiel des défis de notre Anti-Roadmap pour 2026. Nous avons trouvé le chemin, et nous avons construit à pleine vitesse depuis. Trio est une IA du monde réel qui fonctionne, pas un logiciel de présentation — il fonctionne sur les caméras déjà là et les transforme en valeur dès le premier jour.
Le lancement officiel est proche, et l'avenir que nous avons promis est presque entre nos mains. Merci de construire avec nous et de rester à l'écoute.
— L'équipe IoTeX
Lectures complémentaires sur les modèles mondiaux
- D. Ha, J. Schmidhuber. World Models. 2018.
- Y. LeCun. Un chemin vers l'intelligence machine autonome. 2022. (introduit JEPA)
- F.-F. Li. Des mots aux mondes : l'intelligence spatiale est la prochaine frontière de l'IA. 2025. (World Labs)
- D. Hafner, W. Yan, T. Lillicrap. Former des agents à l'intérieur de modèles mondiaux évolutifs (DreamerV4). 2025.
- Meta AI. V-JEPA 2. 2025.
- DeepMind. Genie 3. 2025.
- NVIDIA. Cosmos World Foundation Model Platform for Physical AI. 2025.
- Wayve. GAIA-2 : un modèle mondial multi-caméras contrôlable pour la conduite. 2025.