
Memperkenalkan Trio — Model Dunia untuk Operasi Fisik
Perbarui status IoTeX mengenai Trio, AI dunia nyata, dan jawaban kami untuk tantangan pertama dari Anti-Roadmap.
Pada bulan Maret, IoTeX menerbitkan Anti-Roadmap untuk 2026 — tiga tantangan alih-alih garis waktu. Tantangan 1 adalah yang eksistensial: menjadi antarmuka AI untuk dunia fisik. Jawaban kami sangat konkret — visi pertama, mengubah setiap siaran langsung menjadi kecerdasan yang dapat ditindaklanjuti oleh operasi fisik Anda secara langsung. Jawaban itu adalah Trio, sebuah model dunia untuk operasi fisik, dibangun di MachineFi Lab oleh tim inti di balik IoTeX. Kami menerima tantangan itu, dan sekarang kami sedang mengirimkan.
Sepanjang sejarah, dunia fisik dijalankan oleh manusia. Seseorang mengamati apa yang terjadi, menilai apa artinya, dan bertindak — mengemudikan truk, bekerja di jalur produksi, berjalan di lantai. Persepsi, prediksi, tindakan: siklus itu selalu membutuhkan manusia di dalamnya.
AI pertama-tama mengubah dunia digital — bahasa, kode, gambar. Sekarang mulai pada dunia fisik. AI yang mengemudikan mobil melalui lalu lintas langsung. AI yang belajar permainan video dengan membayangkan bagaimana cara bermain. Robot yang melipat tumpukan pakaian. Bagian di bawah semua itu — yang memungkinkan mesin mengamati situasi, membayangkan apa yang terjadi selanjutnya, dan bertindak berdasarkan itu — adalah model dunia. Trio adalah jenis model dunia baru: yang memberi AI mata pada seluruh operasi, secara langsung.

Yang lainnya sempit dengan tujuan: satu mobil, satu permainan, satu robot, satu tugas. Namun permukaan fisik terbesar dari semua itu sudah terhubung dan mengamati — kamera di atas setiap gudang, toko, pabrik, dan lantai perawatan… Sebuah model dunia yang berjalan pada itu — pada seluruh operasi, secara langsung — adalah persis antarmuka yang dipanggil Tantangan 1. Itu adalah tujuan Trio dibangun.
Apa itu Trio
Perhatikan apa yang umum dari keempat itu: masing-masing menjalankan satu hal — satu mobil, satu permainan, satu robot, satu dunia virtual. Tidak ada dari mereka yang menjalankan sebuah operasi. Dan di situlah sebagian besar ekonomi fisik sebenarnya berada — sebuah restoran saat jam makan siang, sebuah pencucian mobil yang menggerakkan mobil melalui tempatnya, sebuah gudang yang memuat truk, sebuah toko yang bekerja di lantainya, sebuah jalur pabrik — tempat-tempat dengan puluhan orang, kendaraan, dan mesin yang bergerak sekaligus, sepanjang waktu, semuanya di depan kamera yang tidak ada seorang pun yang memiliki waktu untuk menontonnya.

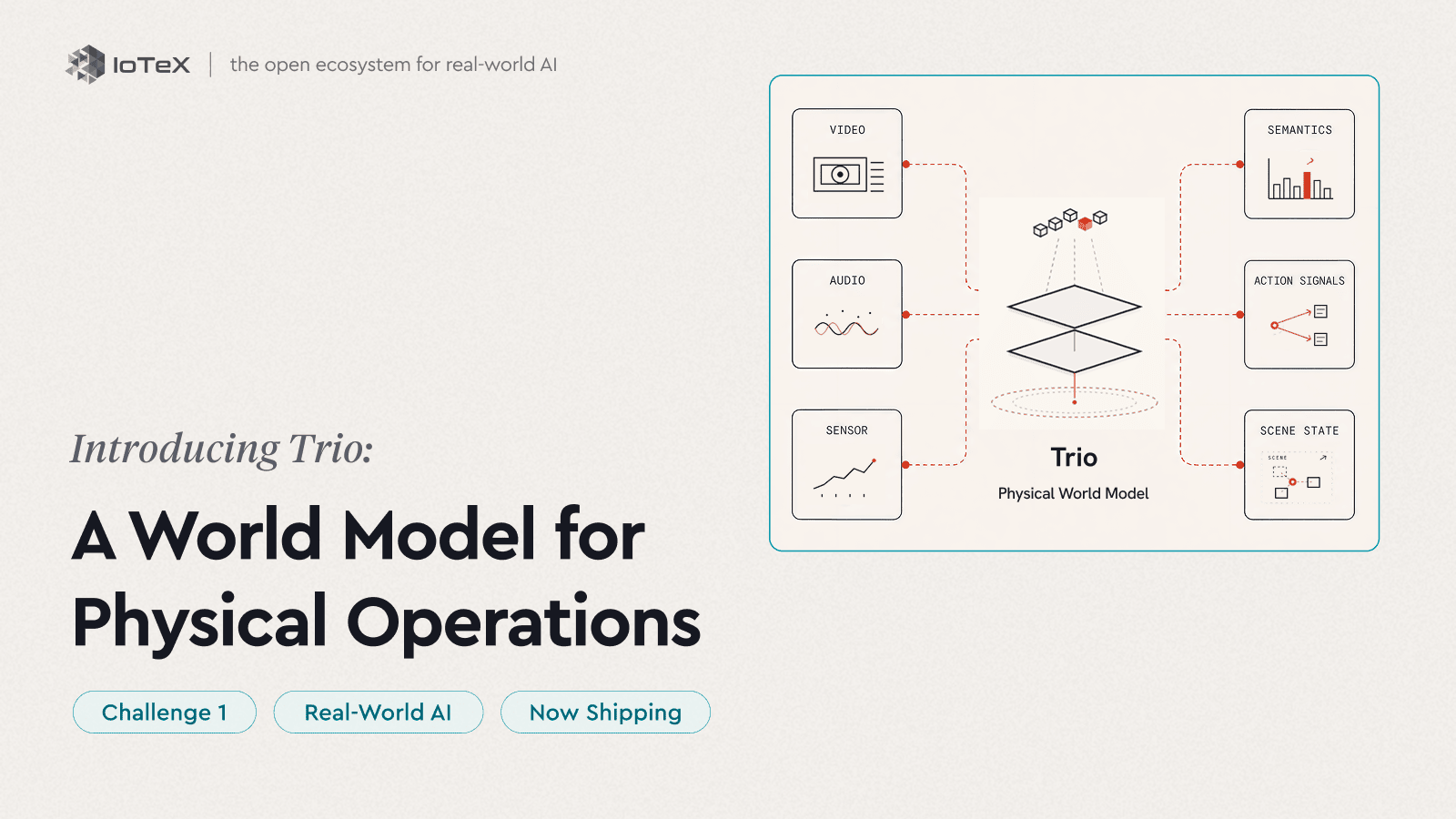
Itulah tujuan Trio. Trio adalah model dunia kami untuk operasi fisik — bukan satu model monolitik, tetapi rangkaian tiga produk yang bersama-sama mengamati, memprediksi, dan bertindak pada operasi langsung. Di mana model bahasa mempelajari bagaimana teks berfungsi, Trio mempelajari bagaimana suatu tempat berfungsi — apa yang ada di dalamnya, bagaimana ia bergerak, apa yang terjadi selanjutnya — untuk operasi Anda, dari kamera dan sensor yang sudah Anda miliki. Kami tidak menggantikan model bahasa; kami memberikannya dunia fisik.
Trio menjalankan siklus itu dalam tiga tahap — dan ia dikirimkan dalam urutan itu. Persepsi adalah hidup hari ini; wawasan dan tindakan adalah apa yang berikutnya.
PERSEPSI → PREDIKSI → TINDAKAN
- Persepsi — Lihat · Pahami — Trio-Retina · Trio-Lumen — Saat ini
- Prediksi — Ramalkan · berpikir ke depan — Berikutnya
- Tindakan — Tutup siklus — Nanti
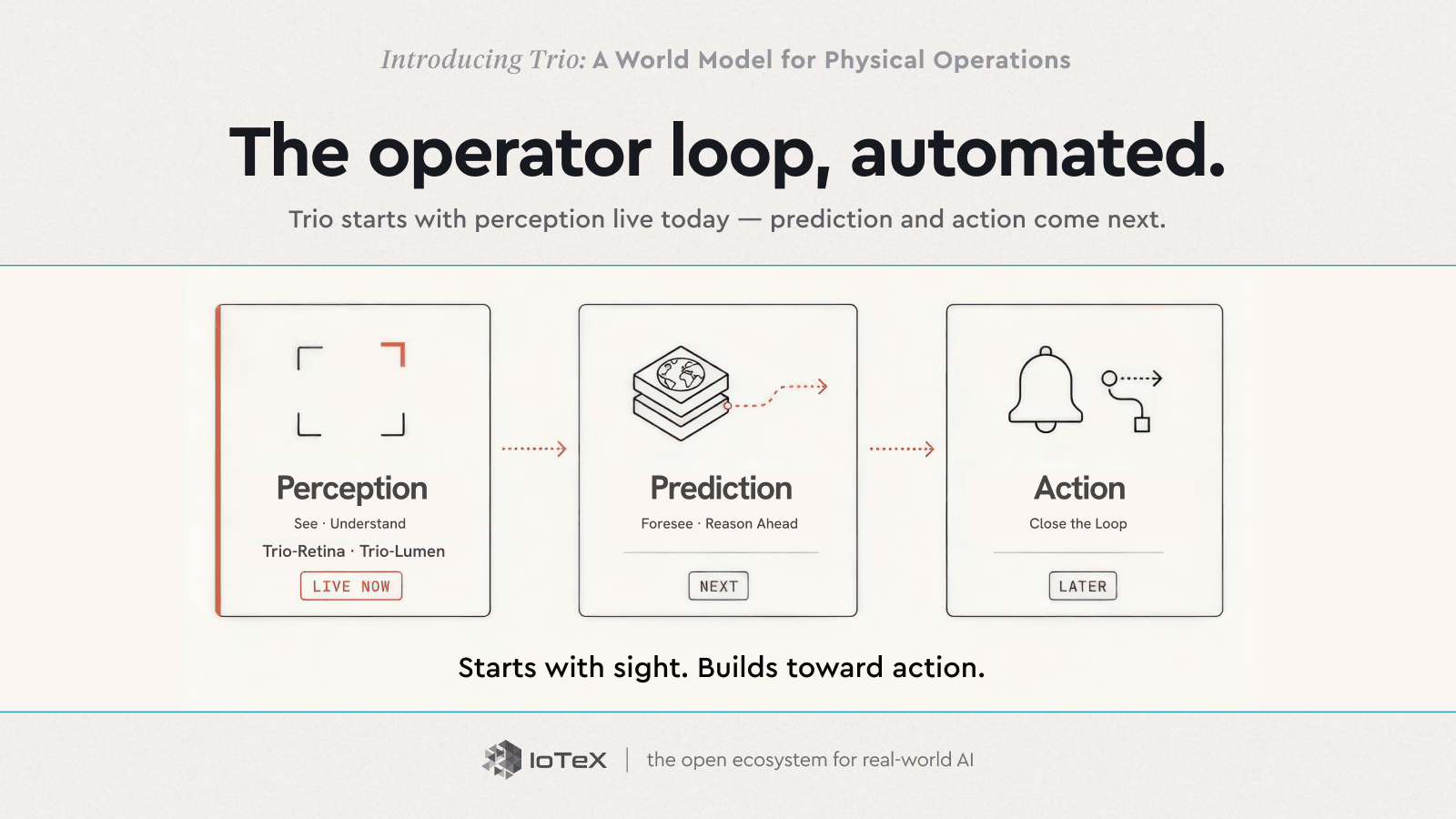
Saat ini, dua dari produk tersebut sudah nyata dan ada di tangan Anda. Trio-Retina (Lihat) mengubah aliran kamera menjadi satu standar, pembacaan langsung tentang apa yang terjadi — siapa di mana, apa yang mereka lakukan, ke mana mereka pergi. Trio-Lumen (Pahami) membuatnya dapat diprogram dalam bahasa Inggris sederhana — "tandai siapa pun di dok pemuatan setelah jam kerja" — mengawasi setiap bingkai sepanjang waktu dan mengubahnya menjadi kejadian dan peringatan. Persepsi dan pemahaman, dikirim hari ini.
pip install trio-retinaTrio-Retina adalah sumber terbuka — berjalan di mesin Anda sendiri, atau coba secara langsung di Playground.Dua hal ini adalah fondasi yang menjadi dasar yang lainnya. Pandangan ke depan dan tindakan — mengantisipasi masalah sebelum terjadi, kemudian bertindak di lapangan — adalah tahap berikut dari loop. Urutannya disengaja: Anda tidak dapat melihat apa yang tidak dapat Anda lihat, jadi kami membangun penglihatan terlebih dahulu.
Sebuah model yang dilatih di internet terbuka belajar bagaimana dunia terlihat. Trio belajar bagaimana operasi Anda berjalan.
Bagaimana Itu Terlihat di Dalam Satu Gudang
Hilangkan abstraksi. Sebuah dock pemuatan, di tengah shift. Sebuah forklift mundur keluar dari sebuah bay; seorang pekerja melangkah keluar dari antara dua rak di jalur yang melintasinya. Keduanya belum dapat melihat satu sama lain.
Lihat — Trio-Retina, yang berjalan di sebuah kotak kecil di samping kamera, sudah memiliki keduanya sebagai objek yang dilacak: forklift dan orang, posisi mereka, dan ke mana masing-masing akan menuju.
Antisipasi — model dunia Trio menjalankan dua detik berikutnya ke depan. Kedua jalur berpotongan. Ia telah melihat geometri yang tepat ini berakhir dengan buruk sebelumnya.
Bertindak — sebuah gerbang keselamatan tepi deterministik mengaktifkan alarm perpotongan dalam waktu sekitar 50 milidetik — lebih cepat dari reaksi keduanya — dan forklift diberi sinyal untuk berhenti. Sebuah hampir-terpeleset daripada laporan insiden.
Itu adalah seluruh tesis dalam satu bingkai: bukan rekaman yang Anda ambil setelah sesuatu terjadi, tetapi keputusan yang dibuat tepat sebelum itu terjadi.

Sebuah Model Dunia Nyata — dan Bagaimana Model Kami Berbeda
Trio berada di dalam bidang yang bergerak cepat. Model-model dunia adalah tempat banyak pikiran terbaik AI sekarang mengarah. Ide tersebut berakar dari Model Dunia Ha & Schmidhuber (2018) — sebuah agen yang belajar model kompak dari lingkungannya dan "bermimpi" peluncuran di dalamnya. Yann LeCun berpendapat bahwa model dunia prediktif dalam ruang laten (modulnya JEPA) adalah bagian yang hilang dalam jalan menuju kecerdasan mesin otonom; Fei-Fei Li menyebut perbatasan kecerdasan spasial, dan World Labs membangun model yang menghasilkan dunia 3D yang dapat dieksplorasi. Bidang ini secara kasar dibagi menjadi beberapa kubu:
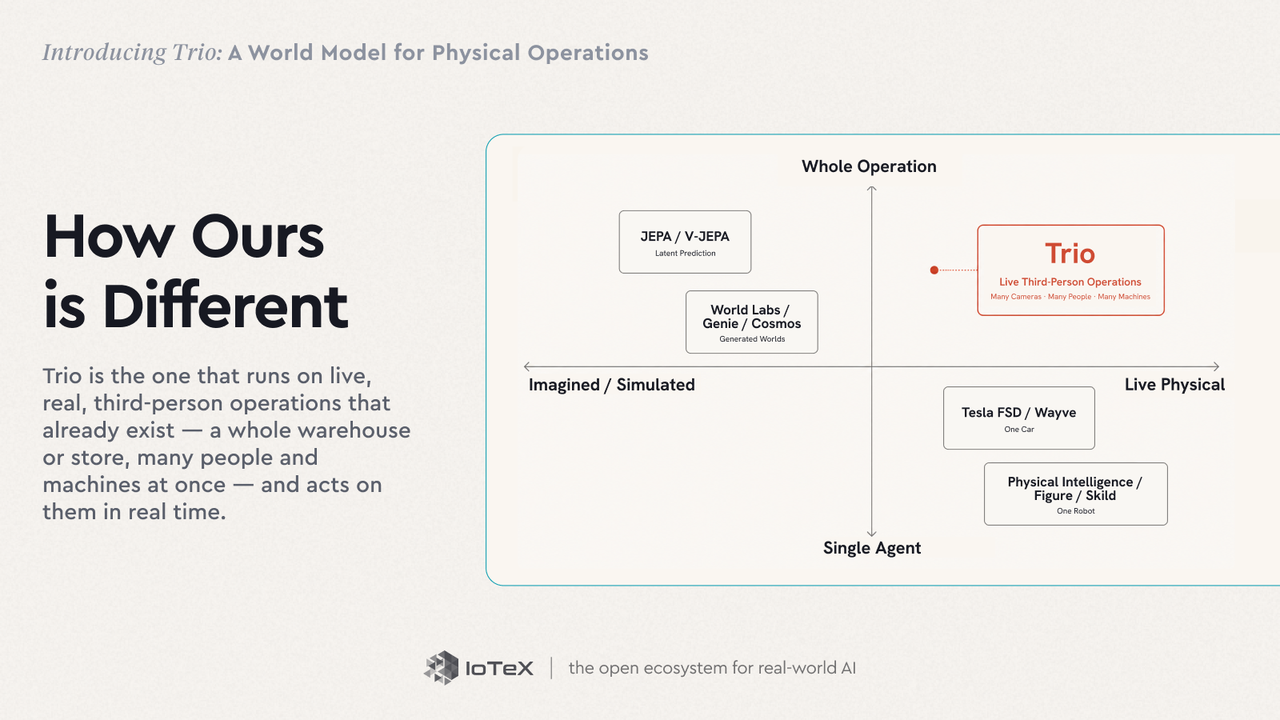
- Prediksi laten — V-JEPA 2 (Meta) dan Dreamer belajar dinamika di ruang laten dan merencanakan di dalamnya.
- Dunia generatif & interaktif — Genie 3 (DeepMind), NVIDIA Cosmos, dan Marble dari World Labs membayangkan dan menghasilkan lingkungan.
- Pengendalian — Tesla FSD dan GAIA-2 Wayve menjalankan model-model dunia yang paling banyak diterapkan di Bumi — untuk satu mobil.
- Robotika — Physical Intelligence, Skild AI, dan Figure membangun model dasar untuk satu robot.
Hampir semua dari mereka baik membayangkan atau mensimulasikan sebuah dunia, atau memodelkan domain egosentris satu agen — satu mobil, satu robot. Trio adalah satu-satunya yang berjalan pada operasi langsung, nyata, dan pihak ketiga yang sudah ada — satu gudang atau toko keseluruhan, banyak orang dan mesin sekaligus — dan bertindak berdasarkan itu secara waktu nyata.

Two axes set Trio apart. Secara teknis — ini kecil, cepat, dan khusus: waktu nyata di tepi, biaya mendekati $0.004 per permintaan, ditagih per keputusan, fondasi beku ditambah adapter kecil per situs (LoRA, dilatih dalam jam GPU) daripada satu model umum raksasa yang dijalankan kembali pada setiap frame. Dalam benchmark streaming OVBench, membungkus model dengan bobot terbuka dalam tumpukan Trio meningkatkan akurasi +2.3 poin murni dari arsitektur, dan aliran persepsinya tanpa batasan menit tetap yang ditetapkan oleh model-model perbatasan. Menurut skenario — ia berjalan pada operasi yang sudah ada, dan bertindak berdasarkan mereka sekarang, alih-alih membayangkan dunia, mengemudikan satu mobil, atau menggerakkan satu robot.
Bagaimana Trio Dibangun
Untuk tim teknis: inilah cara Trio tetap cepat dan cukup murah untuk dijalankan di setiap kamera, sepanjang hari. Jika Anda di sini untuk cerita operasi, langsung saja — bayarannya ada di baris terakhir.
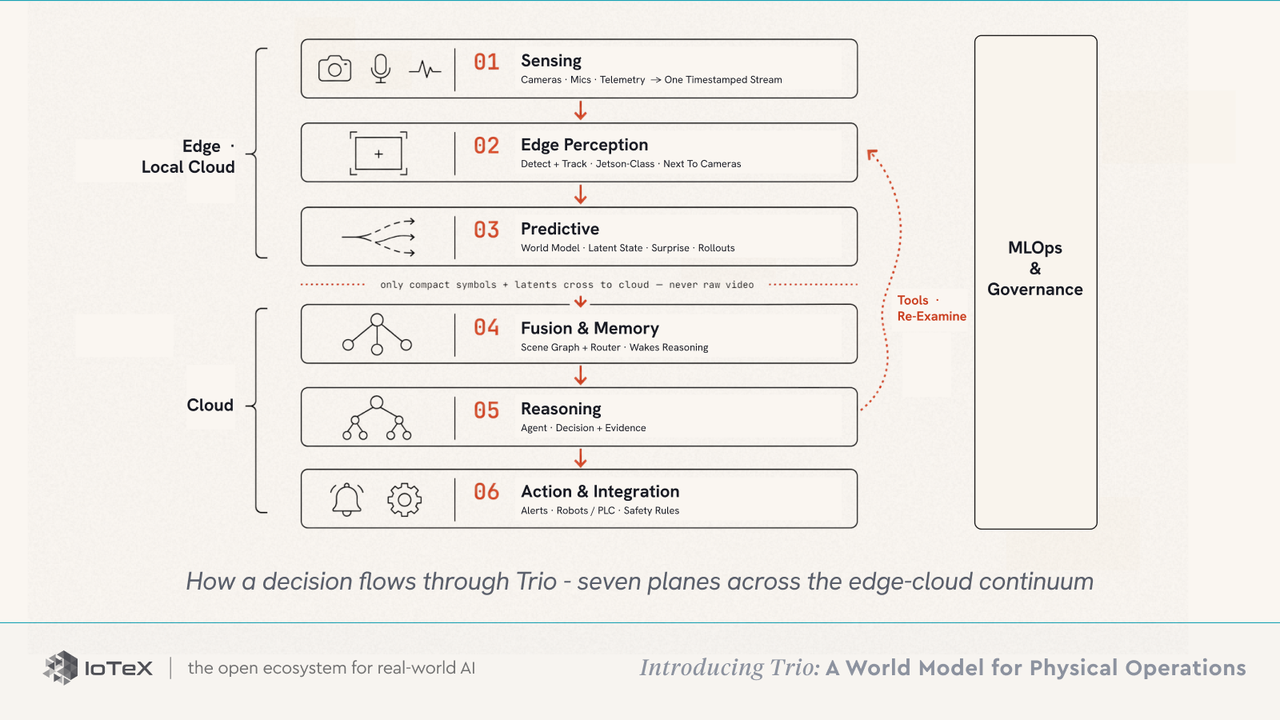
Lima prinsip memegang sistem bersama: setiap antarmuka antara lapisan adalah grafik adegan yang kuat dan dapat diperiksa (tidak pernah vektor yang tidak transparan); sebuah pengatur memiliki biaya, menjalankan lapisan murah secara terus-menerus dan membangkitkan pemikiran yang mahal hanya saat diperlukan; alat-alat bersifat dua arah, sehingga lapisan pemikiran dapat memerintahkan lapisan bawah untuk memeriksa ulang atau mensimulasikan ulang; setiap keputusan disertai dengan buktinya, sehingga seorang operator dapat memeriksa, membantah, dan menyalahi; dan model fondasi tetap beku sementara adapter kecil per penerapan — modul LoRA dan adapter fusi antar lapisan, dilatih dalam jam GPU alih-alih pelatihan ulang penuh — mengkhususkan setiap situs.
Prinsip-prinsip itu diwujudkan sebagai tujuh lapisan — enam dalam jalur satu keputusan, ditambah pemerintahan di seluruhnya: Penginderaan (kamera · mikrofon · telemetri → satu aliran timestamped) → Persepsi Tepi (deteksi + pelacakan, kelas Jetson, di dekat kamera) → Prediktif (model dunia: keadaan laten · kejutan · rollout) → Fusi & Memori (grafik adegan + pengatur yang membangkitkan pemikiran) → Pemikiran (agen → keputusan yang dipasangkan dengan buktinya) → Tindakan & Integrasi (peringatan · robot / PLC · aturan keselamatan independen), dengan MLOps & Governansi di seluruhnya.
Karena persepsi dan prediksi berjalan secara lokal dan hanya simbol serta laten yang compact yang pergi ke cloud — tidak pernah video mentah — Trio ditagih per keputusan, bukan per token per frame.
Di Mana Trio Beroperasi
Gudang adalah satu frame. Restoran, cuci mobil, toko, pabrik yang kami buka — model yang sama menunjuk ke setiap operasi yang berjalan pada kamera, hari ini bersama operator manusia, mengungkap apa yang terlewatkan oleh sistem yang ada:
- Operasi Franchise — Manajemen antrean, pengurangan penyusutan, kepatuhan karyawan, analitik aliran pelanggan.
- Keamanan & Akses — Deteksi intrusi, analisis menunggu, pencegahan tailgating, penegakan setelah jam kerja.
- Logistik & Pergudangan — Status dermaga, waktu tunggu kendaraan, kepatuhan PPE, penegakan prosedur keamanan di seluruh halaman dan lantai.
- Manufaktur & Industri — Pemantauan lini, deteksi cacat, peringatan bahaya di setiap zona lini dan mesin.
- Kota Cerdas — Parkir, aliran lalu lintas, keselamatan publik, pemantauan infrastruktur di seluruh jalan dan transportasi.
- Perawatan Kesehatan & Ilmu Hayati — Deteksi jatuh, pola hunian, pemantauan perilaku di seluruh kamar hunian dan kampus.
- Perhotelan & Tempat Acara — Manajemen kerumunan, kontrol akses zona VIP, respons insiden waktu nyata dalam skala besar.
- Infrastruktur Kritis — Intelijen perimetern 24/7, deteksi intrusi, respons otonom untuk situs yang tidak bisa melewatkan peringatan.
Apa yang Telah Kami Bangun — dan Apa Berikutnya
Trio bukan lagi tesis di papan putih. Laporan teknis v1.0 memformalkan sistem penuh — tumpukan persepsi–prediksi–tindakan, lima prinsip, tujuh lapisan — dengan dua domain referensi yang sepenuhnya dikerjakan (cuci mobil dan gudang), hingga hampir tabrakan forklift-dan-pejalan kaki di atas, ditangkap oleh gerbang keselamatan tepi deterministik yang memicu dalam waktu sekitar 50 milidetik, jauh di bawah batas 100 ms. Trio-Retina adalah sumber terbuka (pip install trio-retina), dan Playground sudah aktif — buka dan saksikan Trio membaca rekaman nyata di browser Anda.
Tiga kekuatan membuat sekarang menjadi momen: silikon tepi akhirnya dapat menjalankan pemikiran operasional waktu nyata tanpa perjalanan bolak-balik ke cloud; pemahaman adegan multi-entitas telah melampaui ambang penelitian deteksi objek tunggal yang sebelumnya tidak terdekat; dan para operator lingkungan fisik siap untuk apa yang mungkin menjadi kemampuan AI yang paling undervalued hari ini — model dunia di atas kamera yang sudah mereka miliki, tanpa perangkat keras baru. Dari sini, Trio tumbuh dalam loop — dari melihat dan memahami hari ini menuju meramalkan dan, pada waktunya, bertindak di lapangan.
Mulai dengan Trio hari ini
Dua cara untuk masuk — keduanya tersedia sekarang:
BUAT DI ATASNYA · PENGEMBANG · Trio-Retina di GitHub. Lapisan persepsi sumber terbuka — lapisan keadaan yang tidak bergantung pada model yang mengubah detektor apa pun menjadi satu aliran standar peristiwa ditambah keadaan laten. pip install trio-retina dan jalankan di mesin Anda sendiri.
MAINKAN DENGANNYA · OPERATOR · Trio-Lumen di platform. Lihat operasi Anda hidup di browser — Trio membaca rekaman nyata sebagai objek dengan keadaan dan kerumunan sebagai aliran, kemudian arahkan ke kamera Anda sendiri dan tanyakan dalam bahasa Inggris yang sederhana.
Trio, IoTeX, dan Ekonomi Mesin
Trio tidak muncul entah dari mana. Itu dibangun di atas satu dekade IoTeX — infrastruktur dan jaringan perangkat terhubung, identitas perangkat (ioID), data mesin yang dapat diverifikasi (Quicksilver), dan pembayaran mesin-ke-mesin (x402) yang dibutuhkan AI dunia nyata untuk hadir di dunia dengan data, identitas, dan kepercayaan di belakangnya. Dan Trio adalah produk untuk mewujudkan visi IoTeX: Tantangan 1 ditetapkan untuk menjadikan IoTeX antarmuka di mana AI melihat, memverifikasi, dan bertindak di dunia fisik, dan Trio adalah yang melihat.
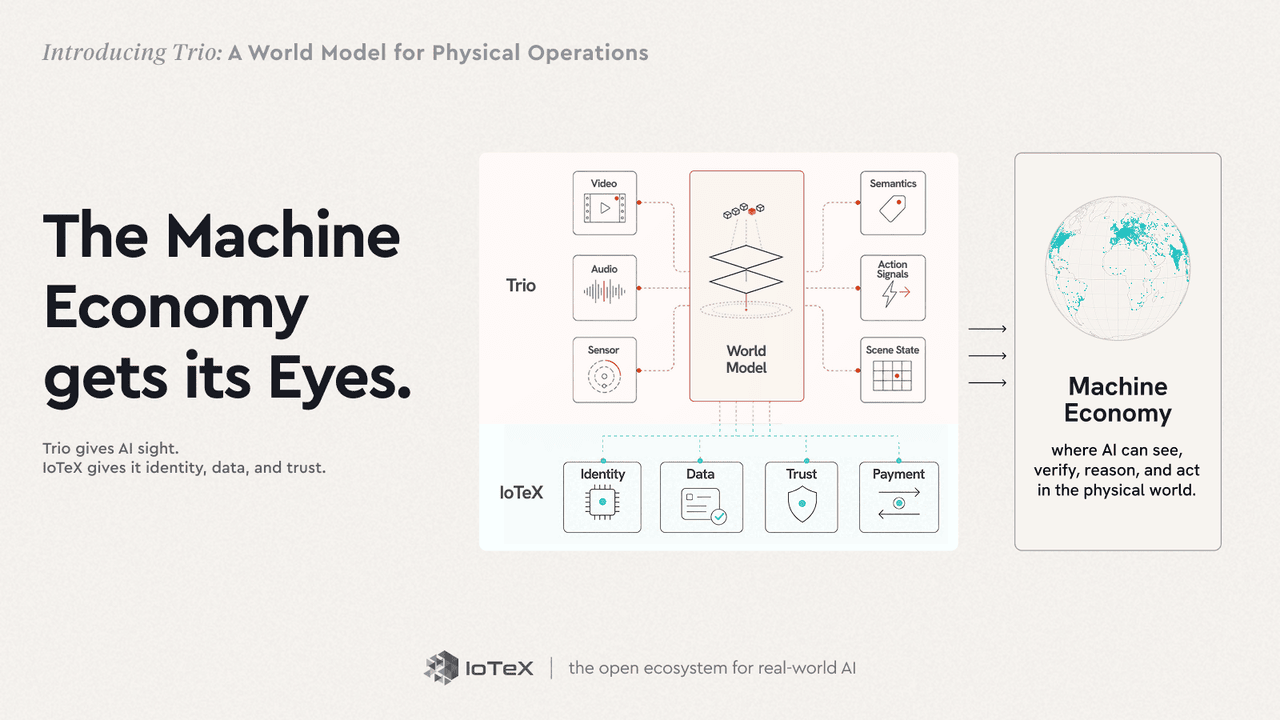
Gabungkan semuanya dan Anda memiliki ekonomi mesin yang dijelaskan di Anti-Roadmap. Mesin membutuhkan tiga hal: untuk melihat dunia, untuk percaya pada apa yang mereka lihat, dan untuk bertindak berdasarkan itu. IoTeX menyediakan kepercayaan terdesentralisasi, sementara Trio menyediakan mata dan telinga untuk memahami realitas fisik — dan otak untuk merenungkan dan bertindak berdasarkan itu.
Terus Kirim...
Tantangan 1 sekarang memiliki jawaban. Berikan AI mata di dunia fisik dan buat itu nyata — itulah tantangan pertama dan paling eksistensial dari Anti-Roadmap kami untuk 2026. Kami menemukan jalannya, dan kami telah membangun dengan kecepatan penuh sejak saat itu. Trio adalah AI dunia nyata yang nyata, bukan perangkat presentasi — ia berjalan di kamera yang sudah ada dan mengubahnya menjadi nilai dari hari pertama.
Peluncuran resmi sudah dekat, dan masa depan yang kami janjikan hampir dalam genggaman kami. Terima kasih telah membangun bersama kami dan tetap berlangganan.
— Tim IoTeX
Bacaan lebih lanjut tentang model dunia
- D. Ha, J. Schmidhuber. Model Dunia. 2018.
- Y. LeCun. Sebuah Jalur Menuju Kecerdasan Mesin Otonom. 2022. (memperkenalkan JEPA)
- F.-F. Li. Dari Kata ke Dunia: Kecerdasan Spasial adalah Perbatasan Berikutnya AI. 2025. (Laboratorium Dunia)
- D. Hafner, W. Yan, T. Lillicrap. Melatih Agen di Dalam Model Dunia yang Dapat Diskalakan (DreamerV4). 2025.
- Meta AI. V-JEPA 2. 2025.
- DeepMind. Genie 3. 2025.
- NVIDIA. Model Fondasi Dunia Cosmos untuk AI Fisik. 2025.
- Wayve. GAIA-2: model dunia multi-kamera yang dapat dikendalikan untuk mengemudi. 2025.