
트리오 소개 — 물리적 작업을 위한 세계 모델
Trio에 대한 IoTeX의 상태 업데이트, 실제 세계 AI 및 반 로드맵의 첫 번째 도전에 대한 우리의 답변.
3월에 IoTeX는 2026년을 위한 반 로드맵을 발표했습니다 — 일정 대신 세 가지 도전 과제. 도전 과제 1은 존재론적 문제였습니다: AI의 물리적 세계에 대한 인터페이스가 되는 것입니다. 우리의 답은 구체적이었습니다 — 비전을 먼저, 모든 실시간 스트림을 물리적 작업에서 실시간으로 작용할 수 있는 지능으로 변환하였습니다. 그 답이 Trio입니다. IoTeX의 핵심 팀이 MachineFi Lab에서 구축한 물리적 작업을 위한 세계 모델입니다. 우리는 도전에 나섰고 지금 배송 중입니다.
역사적으로 물리적 세계는 사람들이 운영해왔습니다. 한 개인이 발생하고 있는 일을 관찰하고 그것의 의미를 판단한 후 행동합니다 — 트럭을 운전하고, 생산 라인에서 일하고, 복도에서 걸어 다니며. 인지하고, 예측하고, 행동하는 루프는 항상 인간이 필요했습니다.
AI는 먼저 디지털 세계를 변화시켰습니다 — 언어, 코드, 이미지. 이제 물리적 세계에서도 시작하고 있습니다. 실시간 교통을 통해 차를 운전하는 AI. 자신이 어떻게 플레이하는지를 상상하여 비디오 게임을 배우는 AI. 세탁물을 접는 로봇. 이 모든 것의 하부 구조 — 기계가 상황을 보고, 다음에 일어날 일을 상상하고, 그에 따라 행동할 수 있게 해주는 것은 세계 모델입니다. Trio는 전체 작업을 실시간으로 보는 AI를 제공하는 새로운 유형의 세계 모델입니다.

그 다른 것들은 의도적으로 좁습니다: 하나의 차, 하나의 게임, 하나의 로봇, 하나의 작업. 그러나 모든 것 중 가장 큰 물리적 표면은 이미 연결되어 감시하고 있습니다 — 모든 창고, 상점, 공장 및 간병인 층 위의 카메라... 그 위에서 운영되는 세계 모델 — 전체 작업, 실시간으로 — 바로 도전 과제 1이 요구했던 인터페이스입니다. Trio가 구축된 이유입니다.
Trio란 무엇인가
이 네 가지가 공통적으로 가지고 있는 점에 주목하세요: 각각은 하나의 일을 수행합니다 — 하나의 차, 하나의 게임, 하나의 로봇, 하나의 가상 세계. 그 중 어느 것도 운영을 실행하지 않습니다. 그리고 그것이 실제 물리적 경제가 존재하는 곳입니다 — 점심 시간에 붐비는 레스토랑, 세차장이 차량을 배출하는 것, 트럭을 적재하는 창고, 바닥에서 일하는 상점, 공장 라인 — 수십 명의 사람, 차량 및 기계가 동시에 움직이고 있는 장소들, 하루 24시간 카메라 속에서 아무도 볼 시간이 없는 곳입니다.

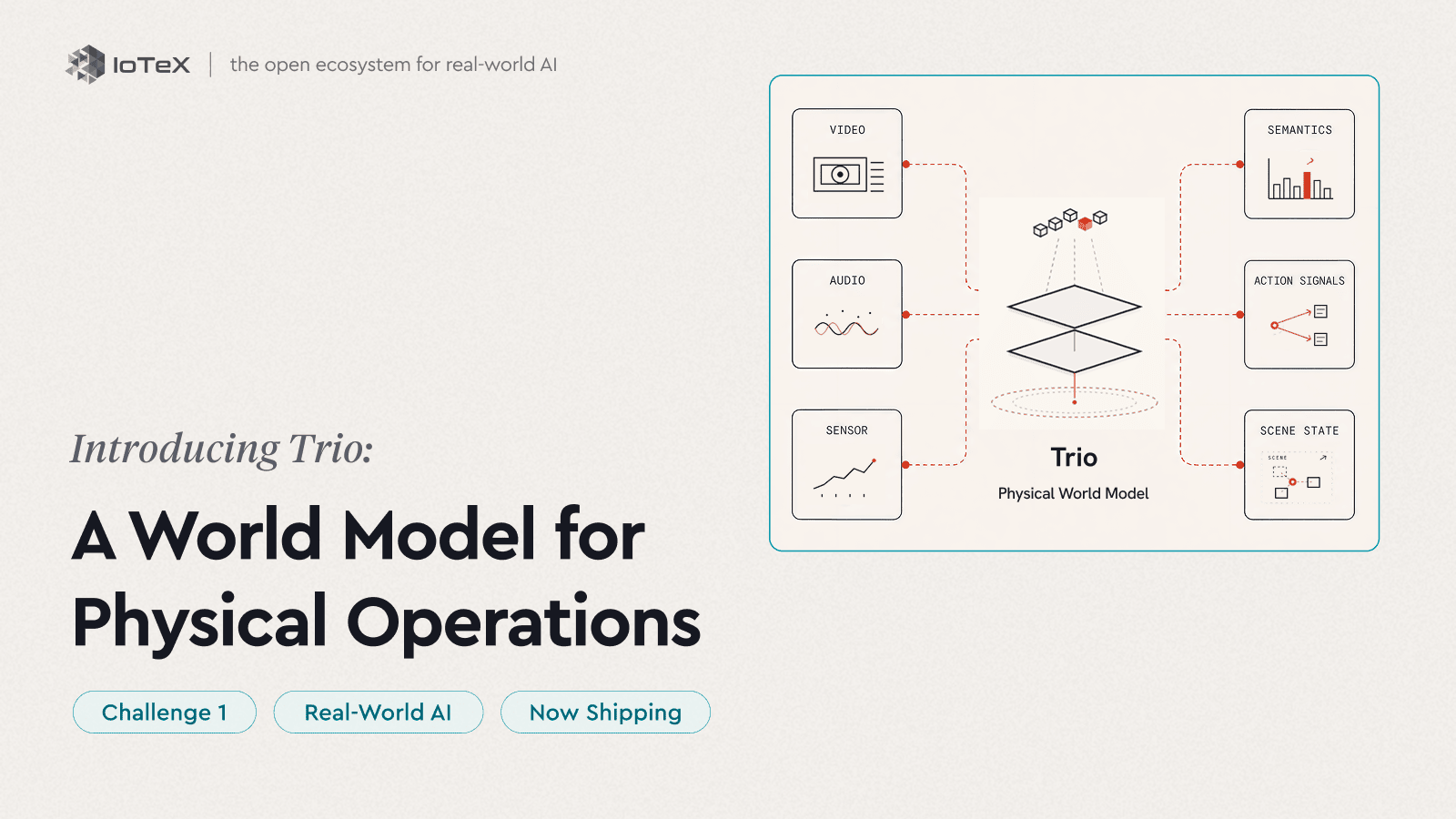
그것이 Trio의 목적입니다. Trio는 물리적 작업을 위한 우리의 세계 모델입니다 — 단일 모놀리식 모델이 아닌, 세 가지 제품의 조합으로 구성되어 있어 함께 실시간 운영을 인지하고, 예측하며, 행동합니다. 언어 모델이 텍스트가 작동하는 방식을 배우는 곳에서, Trio는 장소가 어떻게 작동하는지를 배웁니다 — 그 안에 무엇이 있는지, 어떻게 움직이는지, 다음에 무엇이 일어나는지 — 귀하의 운영을 위해, 이미 가지고 있는 카메라와 센서를 통해. 우리는 언어 모델을 대체하지 않으며; 우리는 그들에게 물리적 세상을 제공합니다.
Trio는 세 단계에서 이 루프를 실행합니다 — 그리고 그 순서로 배송됩니다. 인식은 오늘날 실시간으로 진행되고; 예측과 행동이 다음 단계입니다.
인식 → 예측 → 행동
- 인식 — 보기 · 이해하기 — Trio-Retina · Trio-Lumen — 현재 실시간으로 진행 중
- 예측 — 예견하기 · 미리 판단하기 — 다음 단계
- 행동 — 루프를 닫기 — 나중에
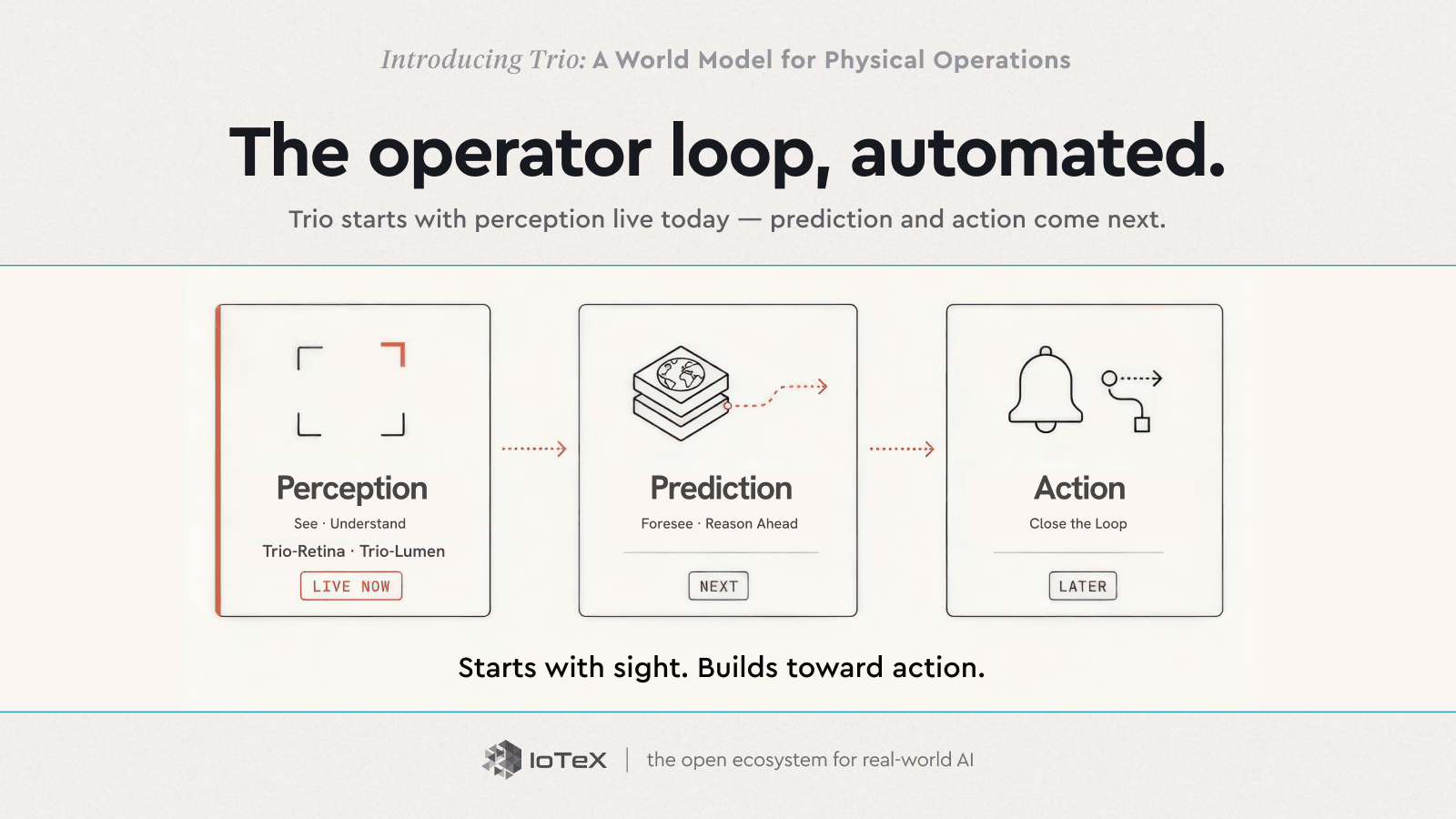
오늘날, 그 두 가지는 실제로 귀하의 손에 있습니다. Trio-Retina (보기)는 모든 카메라 피드를 하나의 표준 실시간 읽기로 변환합니다 — 누가 어디에 있는지, 그들이 무엇을 하고 있는지, 어디로 가고 있는지. Trio-Lumen (이해하기)는 이를 일반 영어로 프로그래밍 가능하게 만듭니다 — "근무 시간 외에 구역에 있는 사람 모두를 플래그 지정" — 매 순간을 하루 24시간 감시하고 이를 사건 및 알림으로 변환합니다. 인식과 이해, 오늘날 배송됩니다.
pip install trio-retinaTrio-Retina는 오픈 소스입니다 — 귀하의 기계에서 실행되거나 플레이그라운드에서 실시간으로 시도해 보세요.이 두 가지는 나머지가 구축되는 기초입니다. 예측과 행동 — 문제를 발생하기 전에 예측하고, 그 후 바닥에서 행동하기 — 가 루프의 다음 단계입니다. 순서는 신중합니다: 보지 못하는 것을 예측할 수는 없으므로 먼저 시각을 구축했습니다.
오픈 인터넷에서 훈련된 모델은 세상이 어떻게 보이는지 배웁니다. Trio는 귀하의 작업이 어떻게 운영되는지를 배웁니다.
하나의 창고에서 어떻게 보이는가
추상화를 제거하세요. 하역 구역, 중간 교대. 지게차가 만에서 후진하고; 한 작업자가 두 개의 진열대 사이에서 나와서 그 사이를 가로지르는 경로에 있습니다. 둘 다 서로를 아직 볼 수 없습니다.
보기 — 카메라 옆의 작은 박스에서 실행 중인 Trio-Retina는 이미 추적된 객체로 두 가지를 가지고 있습니다: 지게차와 작업자, 그들의 위치, 그리고 각각이 향하고 있는 방향입니다.
예측하기 — Trio의 세계 모델이 다음 두 초를 전진시킵니다. 두 경로가 교차합니다. 이 정확한 기하학이 과거에 나쁜 결과를 초래하는 것을 보았습니다.
행동하기 — 결정론적 엣지 안전 게이트가 충돌 알림을 약 50밀리초 내에 발사합니다 — 두 사람 모두 반응할 수 있는 것보다 빠릅니다 — 지게차가 정지를 신호받습니다. 사고 보고서 대신 근접 미스입니다.
이것이 단일 프레임에서 전체 논문입니다: 무언가가 일어난 후에 불러오는 영상이 아니라, 그것이 일어나기 직전에 내린 결정입니다.

실제 세계 모델 — 그리고 우리의 차별점
Trio는 빠르게 움직이는 분야 안에 있습니다. 세계 모델은 지금 많은 AI의 최상위 인재들이 지향하는 곳입니다. 이 아이디어는 Ha & Schmidhuber의 세계 모델 (2018)로 거슬러 올라갑니다 — 에이전트가 환경의 압축 모델을 학습하고 그 안에서 "꿈꾸는" 롤아웃을 하는 것입니다. Yann LeCun은 잠재적 공간에서의 예측 세계 모델 (그의 JEPA)이 자율 기계 지능으로 가는 길에 누락된 조각이라고 주장합니다; Fei-Fei Li는 최전선이 공간 지능이라고 부르며, 그녀의 World Labs는 탐색이 가능한 3D 세계를 생성하는 모델을 구축합니다. 이 분야는 대체로 다음과 같은 진영으로 나뉩니다:
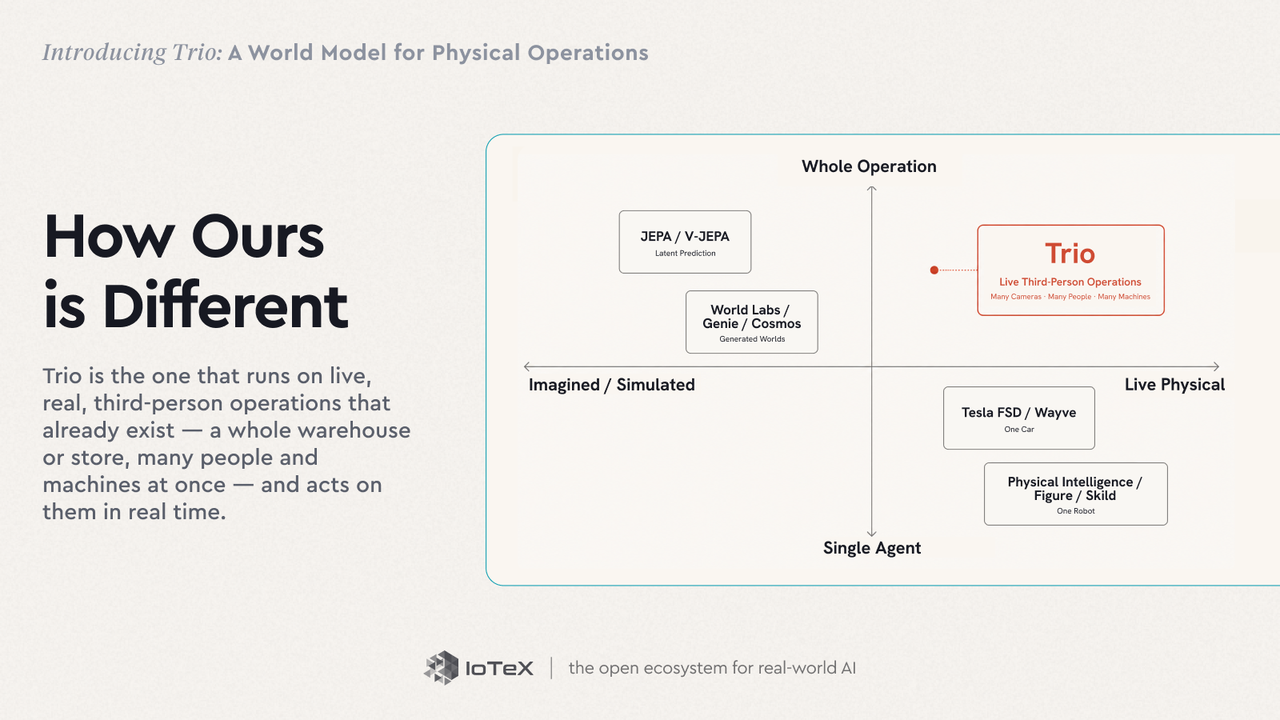
- 잠재 예측 — V-JEPA 2 (Meta)와 Dreamer 계열은 잠재 공간에서 역학을 배우고 그 안에서 계획합니다.
- 생성적 및 대화형 세계 — Genie 3 (DeepMind), NVIDIA Cosmos, 및 World Labs의 Marble은 환경을 상상하고 생성합니다.
- 주행 — Tesla FSD 및 Wayve의 GAIA-2는 지구상에서 가장 많이 배포된 세계 모델을 운영합니다 — 하나의 자동차에 대해요.
- 로봇 공학 — Physical Intelligence, Skild AI, 및 Figure는 하나의 로봇을 위한 기초 모델을 구축합니다.
거의 모든 이들은 상상을 하거나 시뮬레이션하는 세계를 만들거나 단일 에이전트의 자아 중심 도메인을 모델링합니다 — 하나의 자동차, 하나의 로봇. Trio는 실시간으로 이미 존재하는 라이브, 실제, 3인칭 작업에서 운영되고 — 전체 창고나 매장을, 동시에 여러 사람과 기계에서 작업합니다 — 그리고 그들에 대해 실시간으로 행동합니다.

두 축이 Trio를 차별화합니다. 기술적으로 — 작고, 빠르며, 전문화되어 있습니다: 실시간 엣지에서, 쿼리당 근처 $0.004의 바닥 가격, 결정 기준으로 청구되며, 고정된 재단 위에 작은 사이트별 어댑터(LoRA, GPU 시간에 훈련됨)가 있는 대신 모든 프레임에서 재실행되는 거대한 일반 모델이 아닙니다. OVBench 스트리밍 벤치마크에서, Trio의 스택에 개방형 가중치 모델을 감싸면 +2.3 포인트의 정확도가 순수하게 아키텍처에서 향상되며, 고정된 분 제한 없이 인식 스트림이 흐릅니다. 시나리오에 따라 — 이미 존재하는 운영에서 실행되며, 이를 지금 행동으로 옮깁니다. 세상을 상상하지 않고, 한 대의 자동차를 운전하거나 한 대의 로봇을 움직이는 것이 아닙니다.
Trio가 구축되는 방식
기술 팀을 위해: Trio가 모든 카메라에서 하루 종일 빠르고 저렴하게 작동하는 방법은 다음과 같습니다. 운영 이야기를 위해 여기에 있는 경우, 스킵하십시오 — 보상은 마지막 줄입니다.
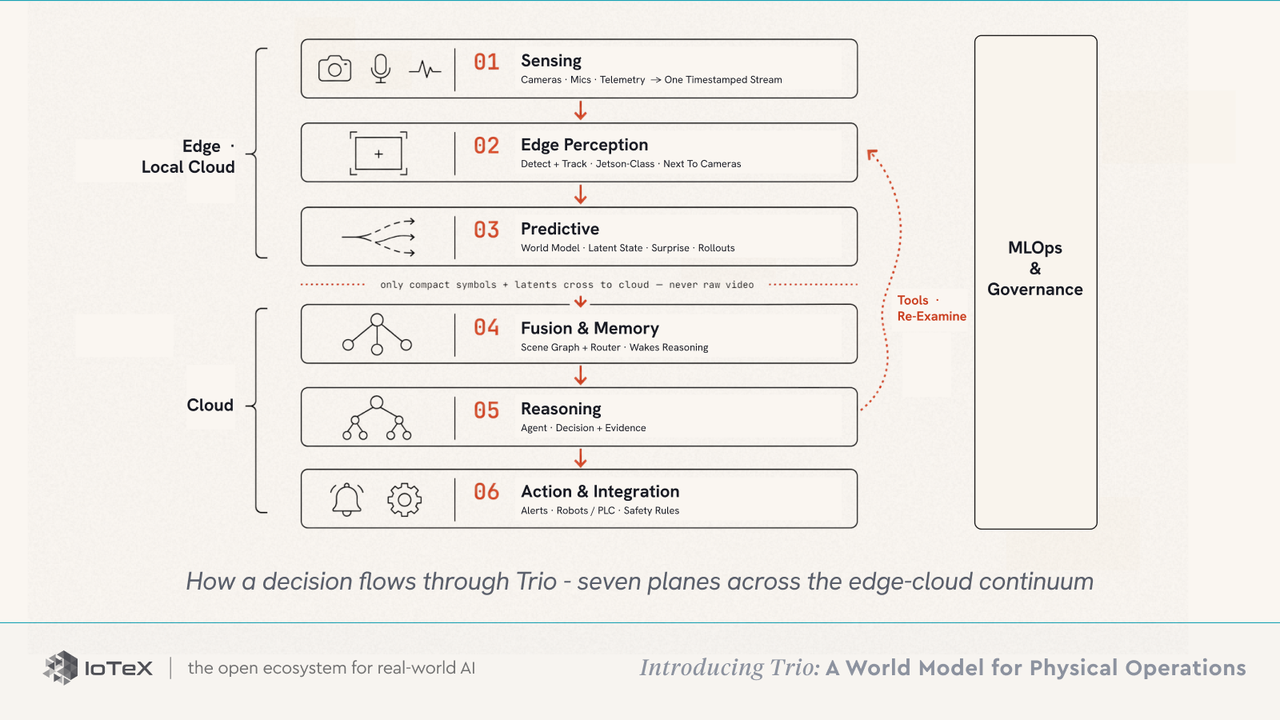
다섯 가지 원칙이 시스템을 유지합니다: 모든 계층 간 인터페이스는 강하게 유형화되고 검사할 수 있는 장면 그래프입니다 (결코 불투명한 벡터가 아님); 라우터는 비용을 소유하며, 저렴한 계층을 지속적으로 실행하고 필요할 때만 비싼 추론을 깨웁니다; 도구는 양방향이므로, 추론 계층이 하위 계층에 재검토하거나 재시뮬레이션하라고 명령할 수 있습니다; 모든 결정은 자신의 증거와 함께 발송되므로 작업자는 이를 검사하고 이의를 제기하며 무시할 수 있습니다; 그리고 기반 모델은 고정된 상태를 유지하고 있으며, 작은 배포별 어댑터 — LoRA 모듈과 크로스 계층 융합 어댑터는 전체 재교육이 아닌 GPU 시간에 훈련되어 각 사이트를 전문화합니다.
이러한 원칙은 한 결정의 경로에서 다섯 개의 평면으로 실현되며, 모든 것에 대해 거버넌스를 포함하여: 감지(카메라 · 마이크 · 텔레메트리 → 한 개의 타임스탬프가 있는 스트림) → 엣지 인식(탐지 + 추적, Jetson 클래스, 카메라 옆) → 예측(세계 모델: 잠재 상태 · 놀라움 · 롤아웃) → 융합 및 메모리(장면 그래프 + 추론을 깨우는 라우터) → 추론(에이전트 → 증거와 함께 결정) → 행동 및 통합(알림 · 로봇 / PLC · 독립 안전 규칙), MLOps 및 거버넌스가 모든 것을 아우릅니다.
감지 및 예측이 로컬에서 실행되고 오직 압축된 기호와 잠재적인 데이터만 클라우드로 전송되므로 — 절대 원시 비디오가 아님 — Trio는 프레임당 토큰이 아닌 결정당 청구됩니다.
Trio가 실행되는 곳
창고는 하나의 프레임이었습니다. 레스토랑, 세차장, 상점, 우리가 시작한 공장 — 카메라에서 실행되는 모든 작업을 가리키는 동일한 모델, 오늘날 인간 운영자와 함께 기존 시스템이 놓치는 것을 드러냅니다:
- 프랜차이즈 운영 — 대기 관리, 줄어든 축소, 직원 준수, 고객 흐름 분석.
- 보안 및 접근 — 침입 탐지, 배회 분석, 꼬리 따르기 방지, 근무 시간 이후 단속.
- 물류 및 창고 관리 — 도크 상태, 차량 대기, PPE 준수, 마당 및 공장에서의 안전 SOP 단속.
- 제조 및 산업 — 라인 모니터링, 결함 탐지, 각 라인 및 기계 구역의 위험 경고.
- 스마트 도시 — 주차, 교통 흐름, 공공 안전, 거리 및 대중 교통 모니터링.
- 건강 관리 및 생명 과학 — 낙상 탐지, 점유 패턴, 거주자 방 및 캠퍼스의 행동 모니터링.
- 환대 및 장소 — 군중 관리, VIP 구역 접근 제어, 대규모 실시간 사건 대응.
- 중요 인프라 — 24/7 perimeter intelligence, 침입 탐지, 경고를 놓칠 수 없는 사이트에 대한 자율 응답.
우리가 구축한 것 — 그리고 다음은
Trio는 더 이상 화이트보드에 대한 논문이 아닙니다. v1.0 기술 보고서는 전체 시스템을 공식화합니다 — 인식–예측–행동 스택, 다섯 가지 원칙, 일곱 개의 평면 — 두 개의 완전히 작동된 참조 도메인(세차장과 창고)으로, 위의 포크리프트-보행자 근접 미스를 포함하여 결정론적 엣지 안전 게이트가 약 50 밀리초 만에 작동하여 100 밀리초의 한계 내에 있습니다. Trio-Retina는 오픈 소스입니다 (pip install trio-retina), 그리고 Playground는 라이브입니다 — 열어서 Trio가 브라우저에서 실제 영상을 읽는 것을 지켜보세요.
세 가지 힘이 지금 이 순간을 만듭니다: 엣지 실리콘이 이제 클라우드 왕복 없이 실시간 운영 추론을 실행할 수 있습니다; 다중 개체 장면 이해가 단일 객체 탐지가 접근할 수 없었던 연구 기준을 넘었습니다; 그리고 물리적 환경의 운영자들은 인공지능 부문에서 아무런 새로운 하드웨어 없이 그들이 이미 소유하고 있는 카메라 위에 세계 모델을 구축할 수 있는 가장 저렴하게 평가받는 능력의 준비가 되어 있습니다. 여기서 Trio는 오늘날의 시각과 이해를 바탕으로 앞으로 예상하고, 결국 바닥에서 행동하는 방향으로 나아갑니다.
오늘 Trio로 시작하세요
두 가지 접근 방법이 있습니다 — 지금 두 가지 모두 사용 가능합니다:
이 위에서 구축하기 · 개발자 — GitHub의 Trio-Retina. 모든 탐지기를 하나의 표준 이벤트 스트림과 잠재 상태로 변환하는 모델 불문의 상태 계층인 오픈 소스 인식 계층입니다. pip install trio-retina를 사용하여 자신의 컴퓨터에서 실행하세요.
이것으로 놀아보기 · 운영자 — 플랫폼상의 Trio-Lumen. 웹 브라우저에서 자신의 작업을 살아있게 보세요 — Trio가 상태가 있는 객체와 흐름으로서의 군중을 읽는 실제 영상을 보여줍니다. 그런 다음 자신의 카메라를 가리키고 간단한 영어로 질문하세요.
Trio, IoTeX, 그리고 기계 경제
Trio는 아무데서나 생겨난 것이 아닙니다. 그것은 IoTeX의 10년 위에 세워졌습니다 — 인프라 및 연결된 장치 네트워크, 장치 ID(ioID), 실제 세계 AI가 데이터, 정체성 및 신뢰를 바탕으로 세상에 착륙하는 데 필요한 검증 가능한 기계 데이터(Quicksilver)와 기계 대 기계 결제(x402). 그리고 Trio는 IoTeX의 비전을 구체화하는 제품입니다: Challenge 1은 IoTeX가 AI가 물리적 세계를 보고, 검증하고, 행동하는 인터페이스가 되도록 하여 Trio는 그 시각을 제공합니다.
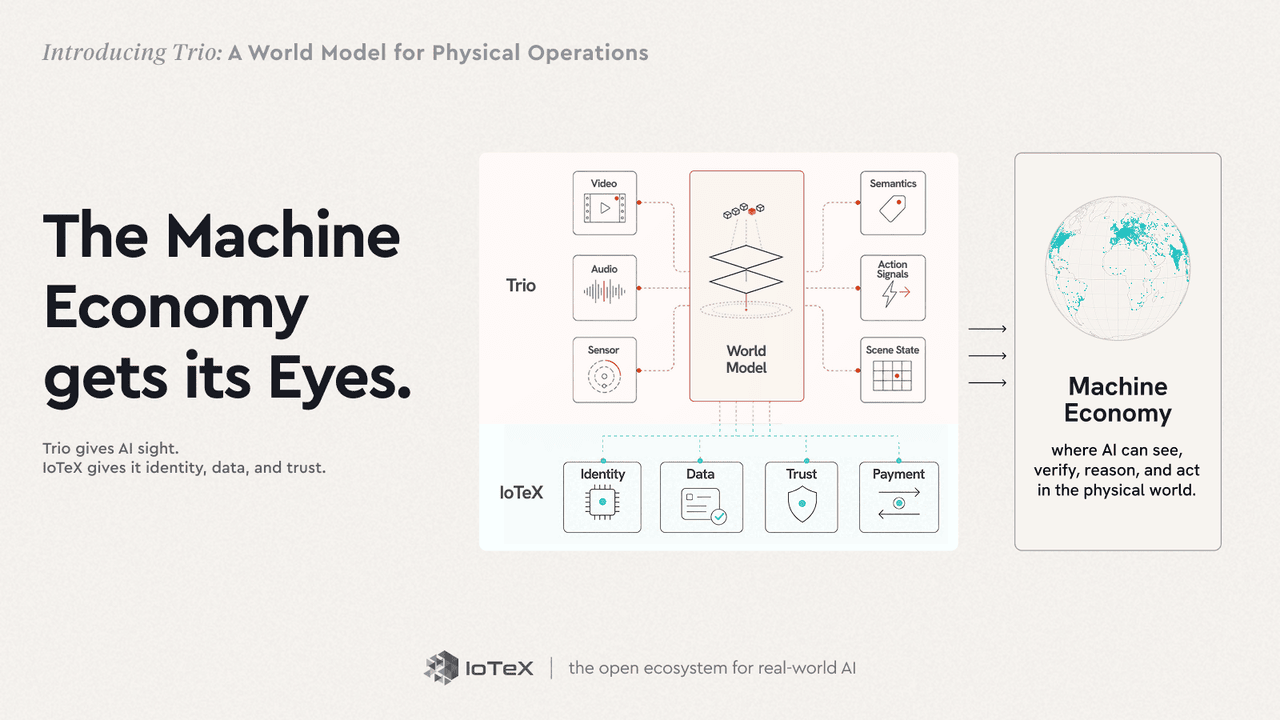
모두 합치면 안티 로드맵에서 묘사한 기계 경제가 탄생합니다. 기계는 세 가지가 필요합니다: 세상을 보고, 그들이 보는 것을 신뢰하며, 그것에 행동하는 것입니다. IoTeX는 분산된 신뢰를 제공하고, Trio는 물리적 현실을 인식할 수 있는 눈과 귀를 제공하며, 그것에 대해 추론하고 행동할 수 있는 두뇌를 제공합니다.
계속 배송하세요...
Challenge 1 now has an answer. 물리적 세계에 대한 AI의 시각을 제공하고 그것을 현실로 만드십시오 — 그것이 우리의 2026년 안티 로드맵의 첫 번째이자 가장 존재론적인 도전이었습니다. 우리는 그 경로를 발견했고 그 이후로 전속력으로 구축해왔습니다. Trio는 슬라이드웨어가 아닌 실세계 AI입니다 — 그것은 이미 존재하는 카메라에서 실행되어 첫날부터 가치를 창출합니다.
공식 출시는 가까워지고 있으며, 우리가 약속한 미래가 거의 손안에 있습니다. 함께 구축해 주셔서 감사드리며 계속 주목해 주시기 바랍니다.
— IoTeX 팀
세계 모델에 대한 추가 독서
- D. Ha, J. Schmidhuber. 세계 모델. 2018.
- Y. LeCun. 자율 기계 지능을 향한 길. 2022. (JEPA 소개)
- F.-F. Li. 단어에서 세계로: 공간 지능은 AI의 다음 경계입니다. 2025. (World Labs)
- D. Hafner, W. Yan, T. Lillicrap. 확장 가능한 세계 모델 내에서 에이전트 훈련 (DreamerV4). 2025.
- Meta AI. V-JEPA 2. 2025.
- DeepMind. Genie 3. 2025.
- NVIDIA. 물리적 AI를 위한 코스모스 세계 방식 플랫폼. 2025.
- Wayve. GAIA-2: 드라이빙을 위한 제어 가능한 다중 카메라 세계 모델. 2025.