
Trioの紹介 — 物理操作のための世界モデル
Trioに関するIoTeXのステータスアップデート、現実世界のAI、そしてアンチロードマップの最初の課題への回答。
3月、IoTeXは 2026年のアンチロードマップを発表しました — タイムラインの代わりに3つの課題がありました。課題1は存在に関わるものでした:AIの物理世界へのインターフェースとなること。私たちの回答は具体的でした — ビジョンを最優先し、任意のライブストリームをリアルタイムで物理操作が実行できるインテリジェンスに変えること。その回答がTrioであり、IoTeXのコアチームによってMachineFi Labで構築された物理操作のためのワールドモデルです。私たちはこの課題に挑み、今、出荷しています。
歴史のすべてにおいて、物理世界は人々によって運営されてきました。人が起こっていることを見て、意味を判断し、行動します — トラックを運転し、ラインで作業し、フロアを歩きます。認識し、予測し、行動する:そのループには常に人間が必要でした。
AIは最初にデジタル世界を変えました — 言語、コード、画像。今、それは物理世界を始めています。ライブトラフィックの中で車を運転するAI。プレイの仕方を想像してビデオゲームを学ぶAI。洗濯物を畳むロボット。それらを支える部分 — 機械が状況を観察し、次に何が起こるかを想像し、行動を起こすことを可能にするのは — ワールドモデルです。Trioは新しいタイプのワールドモデルです:全操作をライブで見せるAIに目を与えるモデルです。

他のものは意図的に狭いです:1台の車、1つのゲーム、1体のロボット、1つのタスク。しかし、最も広い物理表面はすでに配線され、監視されています — すべての倉庫、店舗、工場、ケアフロアの上にあるカメラの… それらの上で動作するワールドモデル — 全操作をライブで — は、課題1が求めていたまさにそのインターフェースです。これこそがTrioが構築されている目的です。
Trioとは何か
これら4つの共通点に気付いてください:それぞれ1つのものを運営しています — 1台の車、1つのゲーム、1体のロボット、1つの仮想世界。いずれも操作を実行しているわけではありません。そして、そこが物理経済の大部分が実際に存在する場所です — ランチラッシュのレストラン、車をベイを通過させる車洗い、トラックを積み込む倉庫、フロアを運営する店舗、工場ライン — 何十人もの人々、車両、機械が動いている場所、時計の周りで、カメラを誰も見る時間がない。

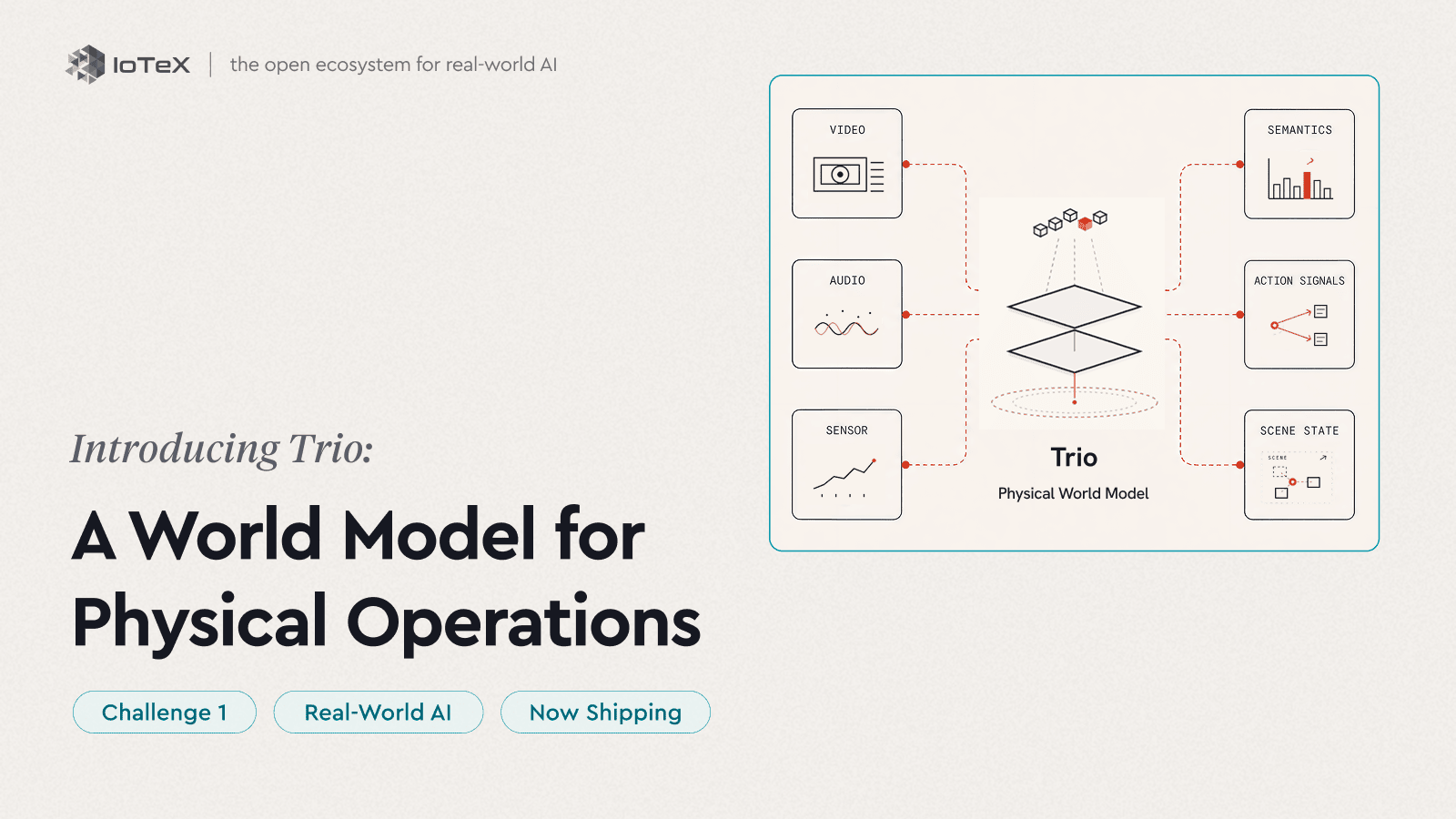
これがTrioの目的です。Trioは物理操作のための私たちのワールドモデルです — 単一のモノリシックモデルではなく、ライブ操作を認識し、予測し、行動するための3つの製品のスイートです。言語モデルがテキストがどのように機能するかを学ぶのに対し、Trioは場所がどのように機能するかを学びます — それに何が含まれ、どのように動き、次に何が起こるか — あなたの操作のために、すでに持っているカメラやセンサーから。私たちは言語モデルを置き換えるのではなく、物理世界を彼らに提供します。
Trioはそのループを3つの段階で実行します — そしてその順序で出荷します。認識は今日ライブです。予測と行動が次です。
認識 → 予測 → 行動
- 認識 — 見る · 理解する — Trio-Retina · Trio-Lumen — 今すぐライブ
- 予測 — 予見する · 先を考える — 次
- 行動 — ループを閉じる — 後で
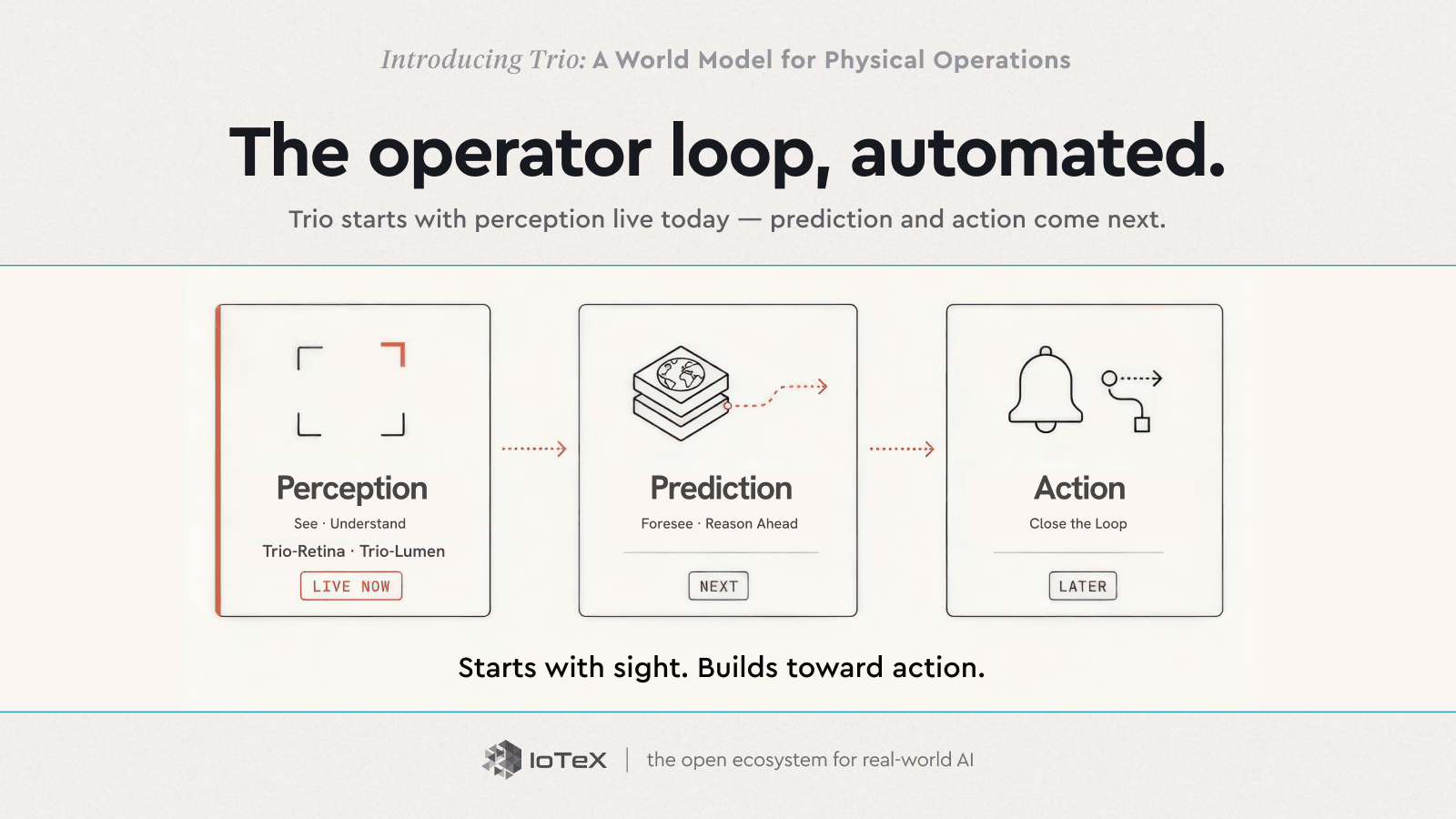
今日、そのうちの2つは実際に存在し、あなたの手の中にあります。 Trio-Retina (見る)は、任意のカメラフィードを標準的なライブレポートに変えます — 誰がどこにいて、何をしており、どこに向かっているのか。 Trio-Lumen (理解する)は、それを平易な英語でプログラム可能にします — "閉店後に荷降ろしドックにいる誰かをフラグ付けする" — 時計の回りに毎フレームを監視し、イベントやアラートに変換します。認識と理解、今日出荷します。
pip install trio-retinaTrio-Retinaはオープンソースであり、あなたのマシン上で実行されるか、Playgroundでライブで試すことができます。これら二つは残りの基盤です。先見性と行動——問題が発生する前に予測し、その後現場で行動する——はループの次の段階です。順序は意図的です:見えないものを予測することはできないので、まず視界を構築しました。
オープンインターネットで訓練されたモデルは、世界がどのように見えるかを学びます。Trioはあなたの操作がどのように機能するかを学びます。
1つの倉庫での見え方
抽象化を取り除きます。シフトの真っ最中の荷捌き用ドック。フォークリフトがベイからバックアウトする; 作業員が二つのラックの間から出て、交差する道を歩いています。お互いをまだ見ることはできません。
見る——カメラの隣にある小さなボックスで実行されているTrio-Retinaは、フォークリフトと人の両方を追跡オブジェクトとしてすでに持ち、その位置とそれぞれが向かっている方向を示しています。
予見する——Trioの世界モデルは次の二秒を前に進めます。二つの道が交差します。これまでこの正確な幾何学が悪い結果に終わったことを見たことがあります。
行動する——決定論的なエッジセーフティゲートが約50ミリ秒で交差点アラームを発信します——どちらの人も反応するよりも早く——そしてフォークリフトに停止するよう信号が送られます。事故報告の代わりにニアミスです。
これは単一のフレームでの全体のテーマです:何かが起こった後に再生する映像ではなく、それが起こる前の瞬間に行われた決定です。

現実の世界モデル — そして私たちの違い
Trioは急速に動く分野の中に位置しています。世界モデルは、多くのAIの優れた頭脳が今向かうところです。このアイデアはHaとSchmidhuberのWorld Models(2018)にさかのぼります——環境のコンパクトなモデルを学ぶエージェントと、その中で「夢見る」ロールアウト。Yann LeCunは、潜在空間における予測的な世界モデル(彼のJEPA)が自律的機械知能への道の欠けている部分だと主張します; Fei-Fei Liはその最前線を空間知能と呼び、彼女のWorld Labsは探査可能な3D世界を生成するモデルを構築しています。分野は大まかに2つの陣営に分かれます:
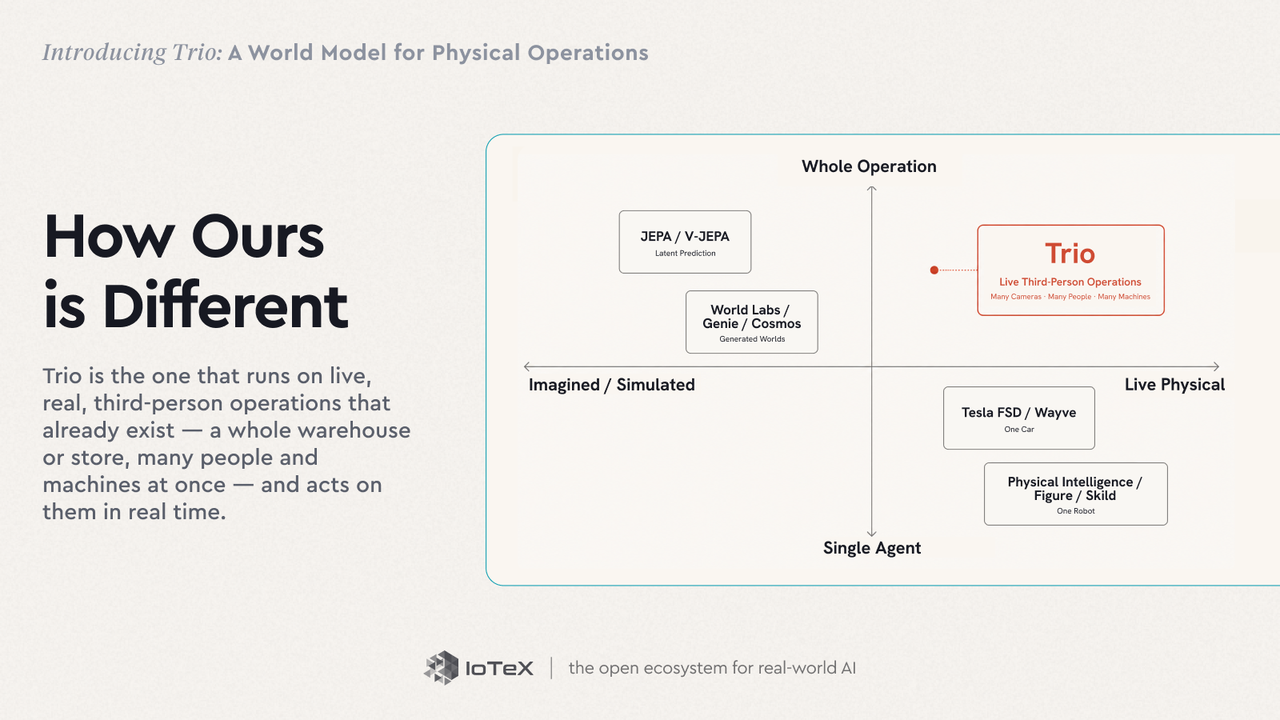
- 潜在予測 — V-JEPA 2(Meta)とDreamerラインは、潜在空間の動力学を学び、その中で計画します。
- 生成的およびインタラクティブな世界 — Genie 3 (DeepMind)、NVIDIA Cosmos、及びWorld LabsのMarbleは、環境を想像し生成します。
- 運転 — Tesla FSDやWayveのGAIA-2は、地球上で最も展開されている世界モデルを動かします — 一台の車に対して。
- ロボット工学 — Physical Intelligence、Skild AI、及びFigureは、単一のロボット用の基盤モデルを構築します。
ほぼすべてが世界を想像またはシミュレーションするか、単一エージェントの自己中心的な領域をモデル化します—一台の車、一体のロボット。Trioはリアルで、実際の、第三者のオペレーションで実行されるもので、すでに存在する——全体の倉庫や店舗、多くの人々や機械が同時に——そしてリアルタイムでそれらに行動します。

トリオは2つの軸で際立っています。 技術的には - 小さくて、速くて、特化しています:エッジでのリアルタイム、1クエリあたり$0.004近くの料金、決定ごとに請求、フローズンな基盤に加え、すべてのフレームで再実行される巨大な一般モデルではなく、小さなサイトごとのアダプター(LoRA、GPU時間でトレーニング済み)。OVBenchのストリーミングベンチマークでは、オープンウエイトモデルをトリオのスタックでラップすると、アーキテクチャによる精度が+2.3ポイント向上し、最前線のモデルが制限している固定の分数制限なしに感知ストリームが動作します。 シナリオにおいて - 既存の運用が実行され、今それに対処します。世界を想像したり、一台の車を運転したり、一台のロボットを動かしたりするのではなく。
トリオの構築方法
技術チームのために:トリオがすべてのカメラで、終日実行できる高速で安価な理由をご紹介します。運用のストーリーを求める方は、先へスキミングしてください - ペイオフは最後の行にあります。
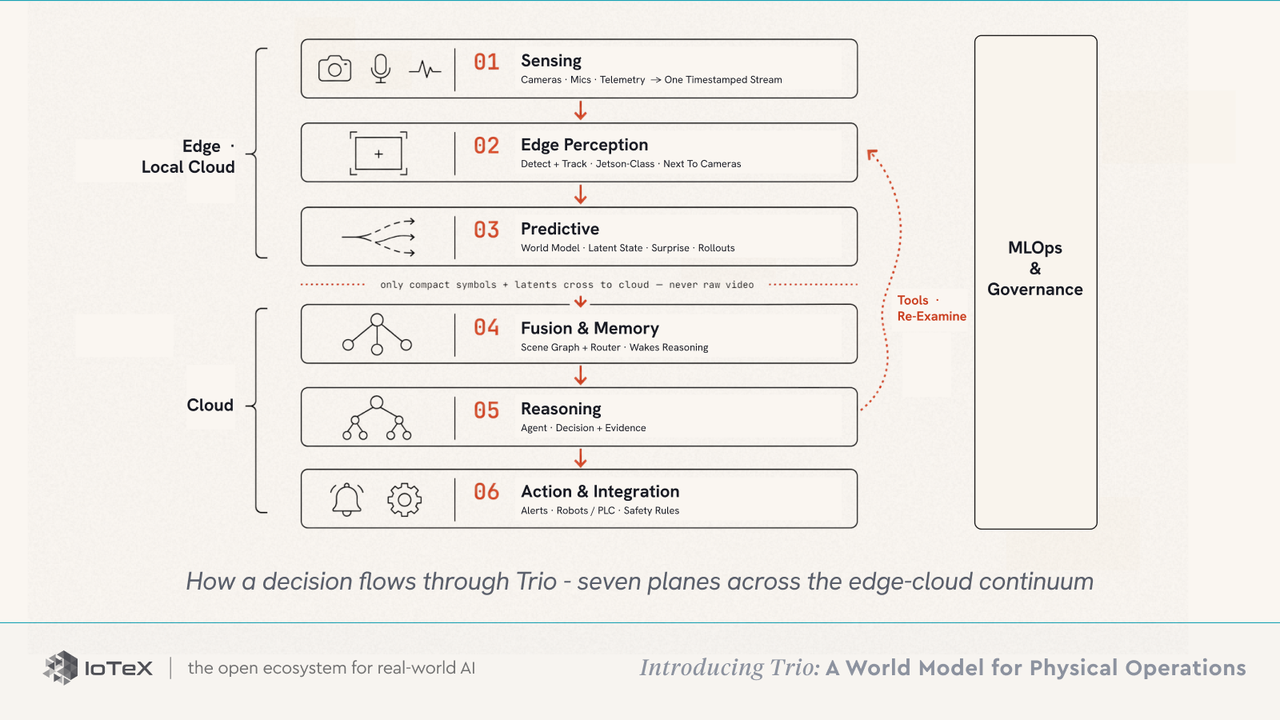
システムを支える5つの原則があります:レイヤー間のすべてのインターフェースは強く型付けされ、検査可能なシーングラフ(不透明なベクトルではない);ルーターはコストを所有し、安価なレイヤーを継続的に実行し、高価な推論を必要なときだけ起こす;ツールは双方向であり、推論レイヤーが下位レイヤーに再審査や再シミュレーションを命令できる;すべての決定はその証拠と共に出荷され、オペレーターはそれを検査、異議を唱え、上書きできる;基盤モデルはフローズンのままで、小さな展開ごとのアダプター - LoRAモジュールとクロスティア融合アダプター、完全な再トレーニングではなくGPU時間でトレーニング - が各サイトを特化させます。
これらの原則は7つのプレーンとして表現されます - 単一の決定の経路において6つ、すべてにわたるガバナンスも含めて: センシング(カメラ·マイク·テレメトリ→1つのタイムスタンプ付きストリーム) → エッジ認識(検出+トラッキング、ジェットソンクラス、カメラの隣に) → 予測(世界モデル:潜在状態·驚き·ロールアウト) → 融合とメモリ(シーングラフ+推論を起こすルーター) → 推論(エージェント→その証拠と結びついた決定) → アクションと統合(アラート·ロボット/PLC·独立した安全規則)、すべてにわたる MLOpsとガバナンス。
感知と予測はローカルで実行され、コンパクトなシンボルと潜在のみがクラウドに移動します - 決して生のビデオは移動しません - トリオは決定ごとに請求され、フレームごとのトークンによってではありません。
トリオが動作する場所
倉庫は1フレームでした。レストラン、洗車、店舗、当初オープンした工場 - 現在、人間のオペレーターと共にカメラで運用されるあらゆるオペレーションを指し示しています、彼らの既存のシステムが見逃すものを明らかにします:
- フランチャイズオペレーション - キュー管理、縮小削減、従業員遵守、顧客フロー分析。
- セキュリティとアクセス - 不正侵入検知、たむろ分析、尾行防止、営業時間外の執行。
- 物流と倉庫業 - ドック状況、車両滞留、PPE遵守、敷地やフロア全体での安全SOP執行。
- 製造業と工業 - 生産ライン監視、欠陥検知、各ラインと機械ゾーン全体での危険アラート。
- スマートシティ - 駐車、交通の流れ、公共の安全、道路や交通機関全体でのインフラ監視。
- ヘルスケアとライフサイエンス - 転倒検知、占有パターン、居住室やキャンパス全体での行動監視。
- ホスピタリティと施設 - 群衆管理、VIPゾーンへのアクセス制御、大規模なリアルタイムインシデント応答。
- 重要インフラ - 24時間365日の周辺情報、侵入検知、警告を逃せないサイト向けの自律的応答。
私たちが構築したもの - 次は何か
トリオはもはやホワイトボード上の論文ではありません。 v1.0技術レポートが完全なシステムを正式化します - 感知–予測–行動スタック、5つの原則、7つのプレーン - 2つの完全に作動するリファレンスドメイン(洗車と倉庫)に下がり、約50ミリ秒で発動する決定論的エッジ安全ゲートによって捉えられたフォークリフトと歩行者の接触事故までを含みます。 Trio-Retinaはオープンソースです(pip install trio-retina)、プレイグラウンド はライブです — 開いて、トリオがブラウザで実際の映像を読むのを見てください。
三つの力が今、この瞬間を作り出しています。エッジシリコンがついにクラウドの往復なしでリアルタイムの運用推論を実行できるようになりました。マルチエンティティのシーン理解が、単一の物体検出が達成したことのない研究の閾値を越えました。そして、物理環境のオペレーターは、既に所有しているカメラの上にワールドモデルを構築するという、今日のAIにおいて最も過小評価されている可能性に対して準備が整っています。ここから、Trioはループを上に成長させます — 今日の視覚と理解から、将来を予見し、時にはフロアで行動することへと。
今日からTrioを始める
二つの方法があります — 両方とも今すぐ利用可能です:
それを基に構築する · 開発者 — GitHubのTrio-Retina。 オープンソースの知覚レイヤー — 任意の検出器を標準のイベントストリームと潜在状態に変えるモデル非依存の状態レイヤー。 pip install trio-retina を実行して、自分のマシンで動かしてください。
それで遊ぶ · オペレーター — プラットフォームのTrio-Lumen。 ブラウザでオペレーションが生き生きと動き出すのを見てください — Trioが実際の映像をオブジェクトとして状態と群衆の流れで読み込み、それを自分のカメラに向けて確認し、簡単な英語で質問します。
Trio、IoTeX、および機械経済
Trioはどこからも来ていません。IoTeXの10年間を基盤に構築されています — インフラストラクチャと接続されたデバイスネットワーク、デバイスのアイデンティティ(ioID)、検証可能な機械データ(Quicksilver)、および現実のAIがデータ、アイデンティティ、信頼を持って世界に実装するために必要な機械間の支払い(x402)。そして、TrioはIoTeXのビジョンを具現化するための製品です:Challenge 1は、AIが物理的世界を見て、検証し、行動するためのインターフェースとしてIoTeXを作成することを目指しました。そしてTrioがその「見る」役割を果たします。
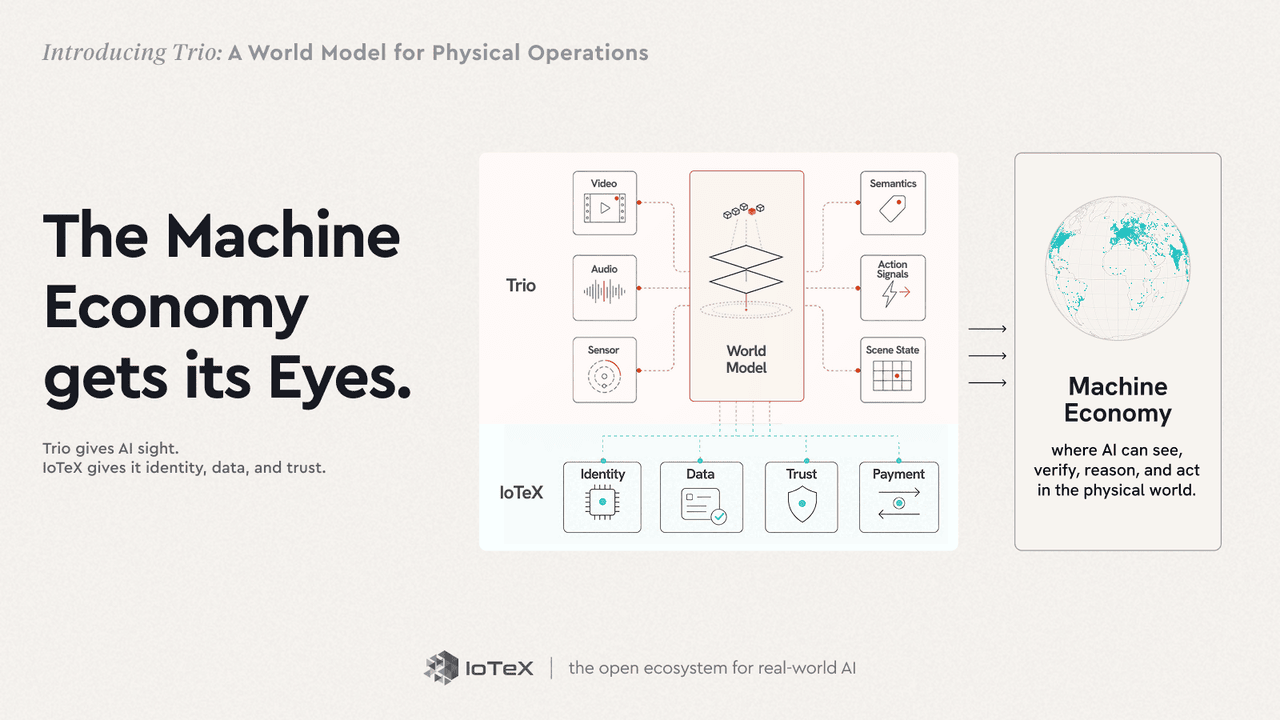
これをまとめると、Anti-Roadmapが描写した機械経済が形成されます。機械は三つのことを必要とします:世界を見ること、見たものを信頼すること、そしてそれに基づいて行動することです。IoTeXは分散型の信頼を提供し、Trioは物理的現実を認識するための目と耳を提供します — そしてそれに基づいて推論し、行動するための脳も提供します。
配送を続ける...
Challenge 1には今、答えがあります。 AIに物理的世界に目を向けさせ、実現する — それが私たちの2026年のAnti-Roadmapの最初の、そして最も存在論的な課題でした。私たちは道を見つけ、以来全速力で構築を進めてきました。Trioは実世界のAIであり、スライドウェアではありません — それは既にあるカメラで動作し、最初の日から価値に変えます。
公式のローンチは近く、約束した未来がほぼ私たちの手の中にあります。私たちと一緒に構築してくれてありがとう、引き続き注目してください。
— IoTeXチーム
ワールドモデルに関するさらなる読書
- D. Ha, J. Schmidhuber. ワールドモデル。 2018年。
- Y. LeCun. 自律型機械知能への道。 2022年。(JEPAを紹介)
- F.-F. Li. 言葉から世界へ:空間知能がAIの次のフロンティアです。 2025年。(ワールドラボ)
- D. Hafner, W. Yan, T. Lillicrap. スケーラブルなワールドモデル内でエージェントを訓練する(DreamerV4)。 2025年。
- Meta AI. V-JEPA 2。 2025年。
- DeepMind. Genie 3。 2025年。
- NVIDIA. 物理AIのためのCosmosワールドファウンデーションモデルプラットフォーム。 2025年。
- Wayve. GAIA-2:運転のための制御可能なマルチカメラワールドモデル。 2025年。